
Exemples des images¶
MNIST¶
Il est souvent possible de réduire considérablement le nombre de variables explicatives. Prenons par exemple les images du MNIST [lecun1998gradient] qui est un ensemble de 70 000 petites images de chiffres manuscrits par des collégiens et des employés du Bureau du recensement américain. Chaque image est étiquetée avec le chiffre qu’elle représente.
from tensorflow.keras.datasets import mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
import matplotlib.pyplot as plt
%matplotlib inline
num = 10
images = X_train[:num]
labels = Y_train[:num]
num_row = 2
num_col = 5
fig, axes = plt.subplots(num_row, num_col, figsize=(1.5*num_col,2*num_row))
for i in range(10):
ax = axes[i//num_col, i%num_col]
ax.imshow(images[i], cmap='gray')
ax.set_title('Label: {}'.format(labels[i]))
plt.tight_layout()
plt.show()
Les pixels de l’image sont presque toujours blancs (ou noir en contrast), ce qui permet de les supprimer complètement du jeu d’entraînement sans perdre beaucoup d’informations. Les pixels ne sont absolument pas importants pour la tâche de classification. De plus, deux pixels voisins sont souvent fortement corrélés : si vous les fusionnez en un seul pixel (par exemple en prenant la moyenne des intensités des deux pixels), vous ne perdrez pas beaucoup d’informations.
sample = 1
image = X_train[sample]# plot the sample
fig = plt.figure(figsize=(12, 7.6))
plt.imshow(image, cmap='gray_r')
plt.show()

Dans le cas des de classification des images, la réduction de la dimensionnalité fait perdre certaines informations, donc même si elle accélère la phase d’entraînement du modèle, elle peut aussi rendre votre modèle légèrement moins performant.
Cela rend également vos pipeline (processus de prédiction en mode production sur les nouvelles données) un peu plus complexes et donc plus difficiles à entretenir. Vous devez donc d’abord essayer d’entraîner votre modèle avec les données originales avant d’envisager d’utiliser la réduction de la dimensionnalité.
Images en très haute définition¶
Nous pouvons faire face des fois à des défis de “taille”, comme la taille des images de très hautes résolution. En effet, certains images nous sont des fois remis avec un très haute résolution. Dans l’exemple ci-dessous, nous avons l’image de l’herbacé Amarante réfléchie Amaranthus retroflexus;

Si l’on compare cette image de semance à celle de l’amarante épineuse (Amaranthus spinosus), on peut voir que ces deux se ressemblent énormément;

Dans d’autres cas, nous avons des images avec plusieurs couches afin de reprodit un effet 3D, cela rend encore les images extrêment en très haute résolution. Dans l’exemple ci-dessous, nous avons une résolution 5000x2000 pixels.

Or, appliquer une réduction de dimension dans de tels problèmes risque de réduire énormément le taux de justesse du modèle de classification.
Imagerie spectrale¶
Certains détails dans les images RGB que nous appercevons avec notre oeil peuvent manquer beaucoup de détail. Par exemple [bianchini2021multispectral] démontre l’importance et la haute performance de l’imagerie spectrale comme outil rapide et polyvalent pour évaluer les attributs de la germination des graines.

Fig. 10 Videometer; capteur d’imagerie spectrale.¶
Dans un article récent [li2020discrimination], un groupe de recherche chinois montre que trois variétés de graines de poivron peuvent être distinguées des images spectrales avec une précision de classification de plus de 97 %. Les classificateurs SVM, CNN et kNN ont été utilisés et comparés. Les tests de pureté génétique rapides et non destructifs ont un potentiel énorme dans l’industrie des semences et cet article montre l’importance de l’imagerie spectrale pour l’analyse des semences dans une autre culture importante.
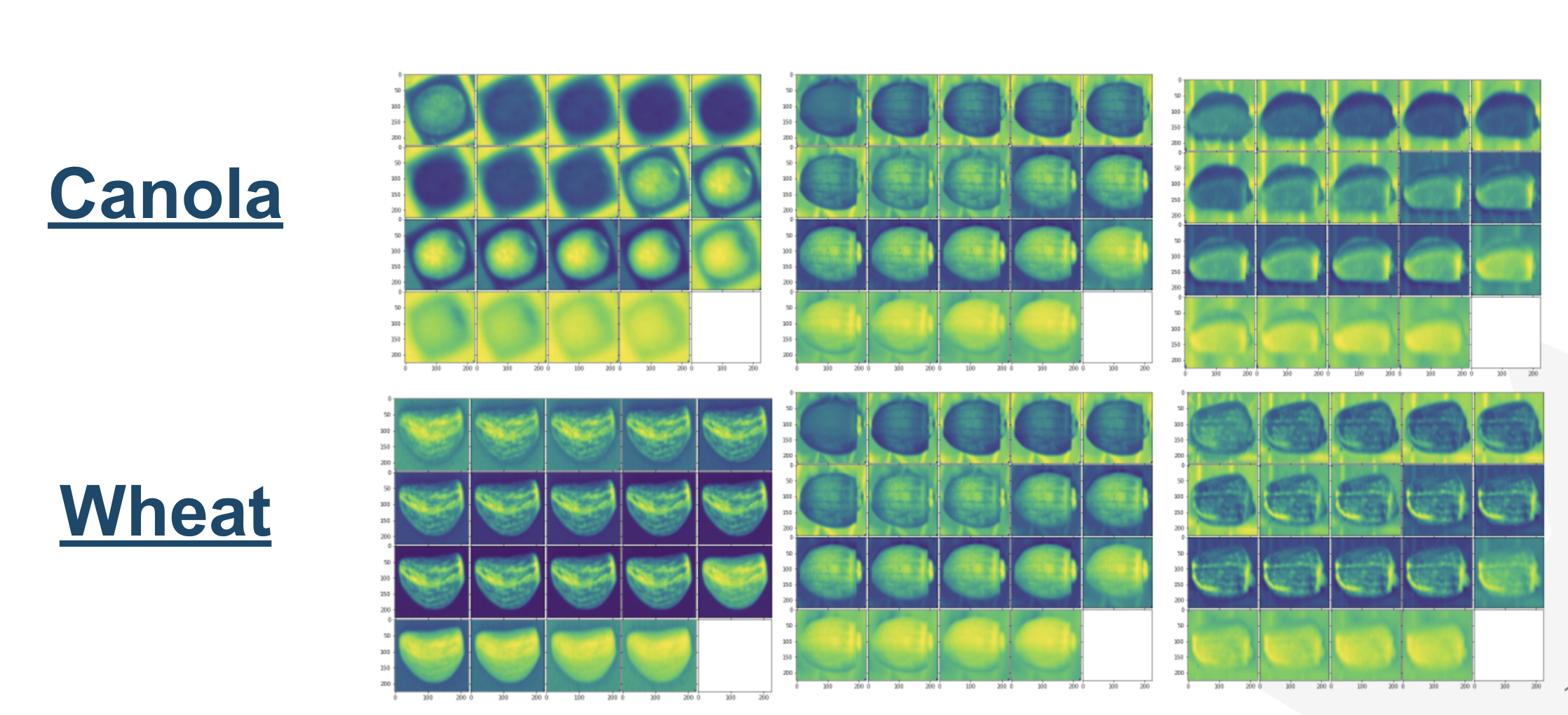
Fig. 11 Exemple d’images spectrales sur 19 canaux des semences¶