
Blocs de codes#
Pour exécuter du code dans un document R Markdown, vous devez insérer un bloc de code (chunk). Il y a trois façons de le faire :
Le raccourci clavier option/alt-Cmd/ctrl-I
L’icône du bouton « Insérer » dans la barre d’outils de l’éditeur.
En tapant manuellement les délimiteurs de chunk
{r} et.
vous connaissez :Cmd/Ctrl + Enter Cependant, les chunks ont un nouveau raccourci clavier : Cmd/Ctrl + Shift/Option + Enter qui exécute tout le code du chunk. Pensez à un chunk comme à une fonction. Un chunk doit être relativement autonome et concentré sur une seule tâche.
nom du bloc code#
On peut donner un nom facultatif aux morceaux : r by-name. Cela présente trois avantages :
Vous pouvez plus facilement naviguer vers des chunks spécifiques en utilisant le navigateur de code déroulant en bas à gauche de l’éditeur de script :
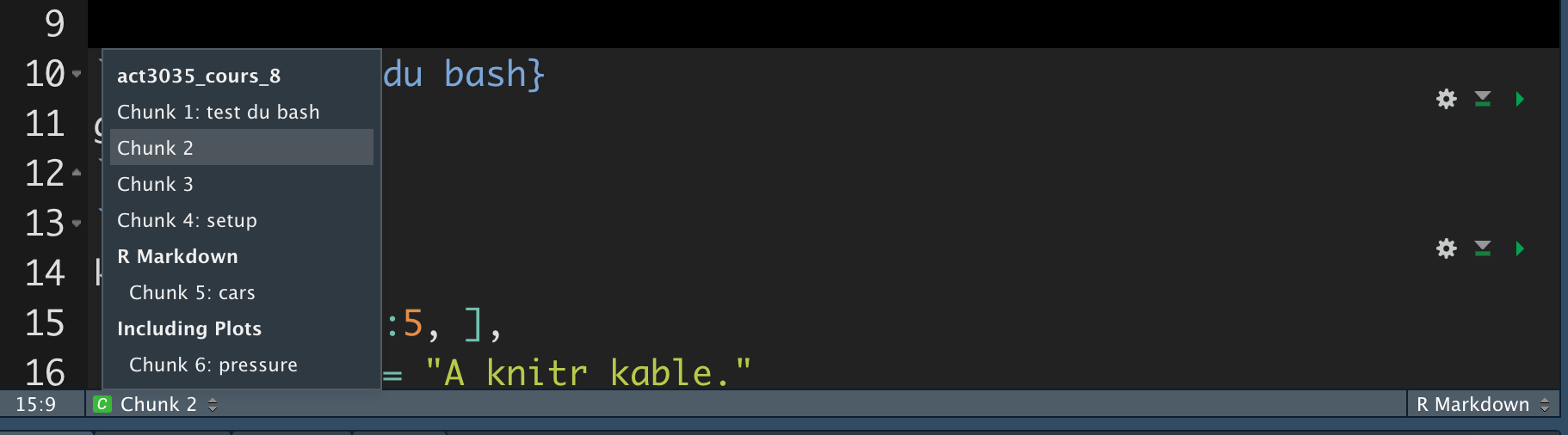
Les graphiques produits par les chunks auront des noms utiles qui les rendront plus faciles à utiliser ailleurs.
Vous pouvez mettre en place des réseaux de morceaux mis en cache pour éviter de refaire des calculs coûteux à chaque exécution. Nous y reviendrons dans un instant.
Il y a un nom de chunk qui donne un comportement spécial : setup. Lorsque vous êtes en mode notebook, le chunk nommé setup sera exécuté automatiquement une fois, avant tout autre code.
Options du bloc code#
La sortie du chunk peut être personnalisée avec des options, des arguments fournis à l’en-tête du chunk. knitr fournit presque 60 options que vous pouvez utiliser pour personnaliser vos chunks de code. Nous allons couvrir ici les options les plus importantes que vous utiliserez fréquemment. Vous pouvez consulter la liste complète.
eval = FALSEempêche le code d’être évalué. (Et évidemment, si le code n’est pas exécuté, aucun résultat ne sera généré). Ceci est utile pour afficher un exemple de code, ou pour désactiver un grand bloc de code sans commenter chaque ligne.include = FALSEexécute le code, mais ne montre pas le code ou les résultats dans le document final. Utilisez ceci pour le code de configuration que vous ne voulez pas encombrer votre rapport.echo = FALSEempêche le code, mais pas les résultats d’apparaître dans le fichier final. Utilisez ceci lorsque vous écrivez des rapports destinés à des personnes qui ne veulent pas voir le code R sous-jacent.message = FALSEouwarning = FALSEempêche les messages ou les avertissements d’apparaître dans le fichier fini.results = 'hide'cache la sortie imprimée ;fig.show = 'hide'cache les graphiques.error = TRUEpermet au rendu de continuer même si le code renvoie une erreur. C’est rarement quelque chose que vous voudrez inclure dans la version finale de votre rapport, mais cela peut être très utile si vous avez besoin de déboguer exactement ce qui se passe dans votre .Rmd. C’est également utile si vous enseignez R et que vous souhaitez inclure délibérément une erreur. La valeur par défaut, error = FALSE, fait échouer le tricotage s’il y a une seule erreur dans le document.
Les tableaux#
Si vous préférez que les données soient affichées avec un formatage supplémentaire, vous pouvez utiliser la fonction knitr::kable. Le code suivant génère
knitr::kable(
mtcars[1:5, ],
caption = "A knitr kable."
)
Table: A knitr kable.
| | mpg| cyl| disp| hp| drat| wt| qsec| vs| am| gear| carb|
|:-----------------|----:|---:|----:|---:|----:|-----:|-----:|--:|--:|----:|----:|
|Mazda RX4 | 21.0| 6| 160| 110| 3.90| 2.620| 16.46| 0| 1| 4| 4|
|Mazda RX4 Wag | 21.0| 6| 160| 110| 3.90| 2.875| 17.02| 0| 1| 4| 4|
|Datsun 710 | 22.8| 4| 108| 93| 3.85| 2.320| 18.61| 1| 1| 4| 1|
|Hornet 4 Drive | 21.4| 6| 258| 110| 3.08| 3.215| 19.44| 1| 0| 3| 1|
|Hornet Sportabout | 18.7| 8| 360| 175| 3.15| 3.440| 17.02| 0| 0| 3| 2|
Mise en cache#
Normalement, chaque knitr d’un document commence à partir d’une page complètement propre. C’est une bonne chose pour la reproductibilité, car cela garantit que vous avez capturé chaque calcul important dans le code. Cependant, cela peut être pénible si vous avez des calculs qui prennent beaucoup de temps.
La solution est cache = TRUE. Lorsque cette option est activée, la sortie du chunk est enregistrée dans un fichier spécialement nommé sur le disque. Lors des exécutions suivantes, knitr vérifiera si le code a changé, et s’il n’a pas changé, il réutilisera les résultats mis en cache.
Le système de cache doit être utilisé avec précaution, car par défaut il se base uniquement sur le code, et non sur ses dépendances. Par exemple, ici le chunk processed_data dépend du chunk raw_data :
```{r raw_data}
rawdata <- readr::read_csv("a_very_large_file.csv")
```
```{r processed_data, cached = TRUE}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
```
Mettre en cache le chunk processed_data signifie qu’il sera réexécuté si le pipeline dplyr est modifié, mais il ne sera pas réexécuté si l’appel read_csv() change. Vous pouvez éviter ce problème avec l’option dependson chunk :
```{r processed_data, cached = TRUE, dependson = "raw_data"}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
```
dependson doit contenir un vecteur de caractères de chaque chunk dont dépend le chunk mis en cache. knitr mettra à jour les résultats pour le chunk mis en cache chaque fois qu’il détectera que l’une de ses dépendances a changé.
Notez que les chunks ne seront pas mis à jour si a_very_large_file.csv change, car la mise en cache de knitr ne suit que les changements dans le fichier .Rmd. Si vous voulez aussi suivre les changements dans ce fichier, vous pouvez utiliser l’option cache.extra. Il s’agit d’une expression R arbitraire qui invalidera le cache à chaque fois qu’il sera modifié.
Une bonne fonction à utiliser est file.info() : elle retourne un tas d’informations sur le fichier, y compris la date de sa dernière modification. Vous pouvez alors écrire :
```{r raw_data, cache.extra = file.info("a_very_large_file.csv")}
rawdata <- readr::read_csv("a_very_large_file.csv")
```
Options globales#
Au fur et à mesure que vous travaillez avec knitr, vous découvrirez que certaines des options par défaut du chunk ne correspondent pas à vos besoins, et vous voudrez les changer. Vous pouvez le faire en appelant knitr::opts_chunk$set() dans un chunk de code.
knitr::opts_chunk$set( echo = FALSE
)
Cela cachera le code par défaut, ne montrant que les parties que vous avez délibérément choisi de montrer (avec echo = TRUE). Vous pourriez envisager de définir message = FALSE et warning = FALSE, mais cela rendrait plus difficile le débogage des problèmes car vous ne verriez aucun message dans le document final.
Code en ligne#
Il existe une autre façon d’intégrer du code R dans un document R Markdown : directement dans le texte, avec : r . Cela peut être très utile si vous mentionnez des propriétés de vos données dans le texte. Par exemple, dans le document d’exemple que j’ai utilisé au début du chapitre, j’avais :
On sait que \(\pi\) est égale à r pi, alors que le nombre de ligne de la bd cars est r nrow(cars)
donnerait ceci:
On sait que 𝜋 est égale à 3.1415927, alors que le nombre de ligne de la bd cars est 50