
Comprendre la régression#
La régression consiste à spécifier la relation entre une seule variable numérique dépendante (la valeur à prédire) et une ou plusieurs variables numériques indépendantes (les prédicteurs). Comme son nom l’indique, la variable dépendante dépend de la valeur de la ou des variables indépendantes. Les formes les plus simples de régression supposent que la relation entre les variables indépendantes et dépendantes suit une droite linéaire.
On se rappelle tous de nos cours de mathématique au secondaire lorsque l’on a appris que les droites peuvent être définies sous la forme d’un axe de pente similaire à \(y=a+b x\). Sous cette forme, la lettre \(y\) indique la variable dépendante et \(y\) indique la variable indépendante. Le terme de pente \(b\) indique de combien les valeurs positives définissent les lignes qui ont une pente ascendante, tandis que les valeurs négatives définissent les lignes qui ont une pente descendante. Le terme \(a\) est appelé d’intercept, car il indique le point où la ligne croise, ou intercepte, l’axe vertical des \(y\). Il indique la valeur de \(y\) lorsque \(x = 0\).
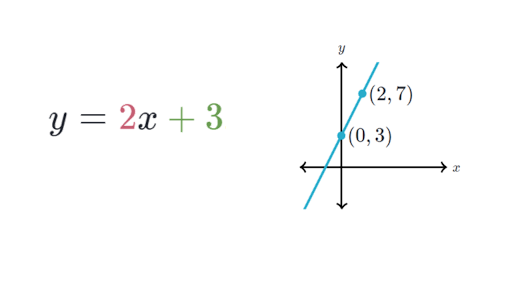
Dans cette section, nous nous concentrerons uniquement sur les modèles de régression linéaire les plus basiques - ceux qui utilisent des lignes droites. Le cas où il n’y a qu’une seule variable indépendante est connu sous le nom de régression linéaire simple. Dans le cas de deux variables indépendantes ou plus, on parle de régression linéaire multiple. Ces deux techniques supposent une seule variable dépendante qui est mesurée sur une échelle continue.
Estimation par moindres carrés ordinaires#
Afin de déterminer les estimations optimales de \(\alpha\) et \(\beta\), une méthode d’estimation connue sous le nom de moindres carrés ordinaires (OLS - ordinary least squares) a été utilisée. Dans la régression OLS, la pente et l’ordonnée à l’origine sont choisies de manière à minimiser la somme des erreurs au carré (SSE - sum of the squared errors ). Les erreurs, également connues sous le nom de résidus, sont la distance verticale entre la valeur y prédite et la valeur y réelle. Comme les erreurs peuvent être des surestimations ou des sous-estimations, elles peuvent être des valeurs positives ou négatives.
Cette équation définit \(\epsilon\) (l’erreur) comme la différence entre la valeur \(y\) réelle et la valeur \(y\) prédite. Les valeurs de l’erreur sont élevées au carré pour éliminer les valeurs négatives et additionnées sur tous les points des données.
La solution pour \(a\) dépend de la valeur de \(b\). Elle peut être obtenue à l’aide de la formule suivante :
On peut montrer que la valeur de \(bb\) qui donne lieu à l’erreur quadratique minimale est :
Si l’on divise le numérateur par \(n\) et le dénominateur par \(n\), on peut remarquer la formule de la variance et de la covariance qui prend place, on peut donc réécrire \(b\) comme:
On peut donc utiliser les fonctions R de bse tel que cov() , var() et mean(). Toutefois, l’estimation manuelle de l’équation de régression est évidemment loin d’être idéale.
R fournit don une fonction permettant d’ajuster automatiquement les modèles de régression. Nous allons bientôt utiliser cette fonction. Avant cela, il est important d’élargir votre compréhension de l’ajustement du modèle de régression en apprenant d’abord une méthode pour mesurer la force d’une relation linéaire. En outre, vous apprendrez bientôt comment appliquer la régression linéaire multiple à des problèmes comportant plus d’une variable indépendante.
Corrélations#
La corrélation entre deux variables est un nombre qui indique dans quelle mesure leur relation suit une ligne droite. Une corrélation est comprise entre -1 et +1. Les valeurs maximale et minimale indiquent une relation parfaitement linéaire, tandis qu’une corrélation proche de zéro indique l’absence de relation linéaire.
r <- cov(x, y) / (sd(x) * sd(y))
ou plus directement:
r <- cor(x, y)
Rappels d’algèbre#
L’inverse d’une matrice \(\left(A^{-1}\right)\) est son inverse multiplicatif. C’est-à-dire que si l’on multiplie la matrice d’origine \((A)\) par son inverse \(\left(A^{-1}\right)\), on obtient une matrice d’identité comportant des \(1\) sur la diagonale et des \(0\) hors diagonale.
Supposons que nous ayons la matrice \(2 \times 2\) suivante :
Son inverse matriciel est
Pour les dimensions supérieures, la formule de calcul de la matrice inverse est plus complexe. En R, nous pouvons utiliser la fonction solve() pour calculer l’inverse de la matrice, si elle existe.
m10<-matrix(1:4, nrow=2)
m10
| 1 | 3 |
| 2 | 4 |
solve(m10)
| -2 | 1.5 |
| 1 | -0.5 |
m10%*%solve(m10)
| 1 | 0 |
| 0 | 1 |
Notez que seules certaines matrices ont des inverses. Il s’agit de matrices carrées, c’est-à-dire qu’elles ont le même nombre de lignes et de colonnes.
Une autre fonction qui peut nous aider à calculer l’inverse d’une matrice est la fonction ginv() du paquetage MASS.
MASS::ginv(m10)
| -2 | 1.5 |
| 1 | -0.5 |
La fonction solve() peut être utilisée pour résoudre des équations matricielles. solve(A, b) renvoie le vecteur \(x\) dans l’équation \(b=A x\) (i.e., \(\left.x=A^{-1} b\right)\).
s1<-diag(c(2, 4, 6, 8))
s1
| 2 | 0 | 0 | 0 |
| 0 | 4 | 0 | 0 |
| 0 | 0 | 6 | 0 |
| 0 | 0 | 0 | 8 |
s2<-c(1, 2, 3, 4)
s2
- 1
- 2
- 3
- 4
solve(s1, s2)
- 0.5
- 0.5
- 0.5
- 0.5
Le tableau suivant résume certaines fonctions de base des opérations matricielles.
Expression |
Description |
|---|---|
|
Transpose |
|
Diagonal |
|
Résout |
|
Matrice inverse de |
|
Somme des lignes d’un objet de type matrice. |
|
même chose mais pour les colonnes |
|
moyenne pour les lignes |
|
moyenne pour les colonnes |
mat1 <- cbind(c(1, -1/5), c(-1/3, 1))
mat1.inv <- solve(mat1)
mat1.identity <- mat1.inv %*% mat1
mat1.identity
| 1.000000e+00 | 0 |
| 1.030921e-17 | 1 |
b <- c(1, 2)
x <- solve (mat1, b)
x
- 1.78571428571429
- 2.35714285714286
Régression linéaire multiple#
La plupart des analyses du monde réel comportent plus d’une variable indépendante. Par conséquent, il est probable que vous utilisiez la régression linéaire multiple pour la plupart des tâches de prédiction numérique.
Nous pouvons comprendre la régression multiple comme une extension de la régression linéaire simple. Dans les deux cas, l’objectif est similaire : trouver les valeurs des coefficients de pente qui minimisent l’erreur de prédiction d’une équation linéaire. La différence essentielle est qu’il existe des termes supplémentaires pour les variables indépendantes additionnelles.
Les modèles de régression multiple se présentent sous la forme de l’équation suivante. La variable dépendante \(y\) est spécifiée comme la somme d’un terme d’interception \(\alpha\) plus, pour chacune des \(i\) caractéristiques, le produit de la valeur \(\beta\) estimée et de la variable \(x\). Un terme d’erreur \(\epsilon\) a été ajouté ici pour rappeler que les prédictions ne sont pas parfaites. Il représente le terme résiduel noté précédemment.
Afin d’estimer les paramètres de régression, chaque valeur observée de la variable dépendante y doit être reliée aux valeurs observées des variables indépendantes x en utilisant l’équation de régression sous la forme précédente.
En notation matricielle, la variable dépendante est un vecteur, Y, avec une ligne pour chaque exemple. Les variables indépendantes ont été combinées dans une matrice, X, comportant une colonne pour chaque caractéristique plus une colonne supplémentaire de valeurs « 1 » pour l’intercept. Chaque colonne a une ligne pour chaque exemple. Les coefficients de régression \(\beta\) et les erreurs résiduelles \(\epsilon\) sont aussi maintenant des vecteurs.
L’objectif est maintenant de trouver \(\beta\), le vecteur des coefficients de régression qui minimise la somme des erreurs quadratiques entre les valeurs \(Y\) prédites et réelles. La recherche de la solution optimale nécessite l’utilisation de l’algèbre matricielle.
Estimation des coefficients#
Soit \( \hat{y}= \hat{\beta}_0 + \hat{\beta}_1 X\) la prédiction pour \(Y\) sur la \(i\)ème valeur de \(X\). Pour chaque point rouge dans la figure ci-dessous, on peut calculer « de combien on s’est trompé » dans note modèle, en calculant la distance (verticale) entre le point rouge et la droite bleue qui la régression linéaire simple de notre jeu de données.
Alors pour chaque point \(i\), nous pouvons écrire \(e_i=y_i -\hat{y}_i\). Nous appelons \(e_i\) le \(i\)ème résidu. Nous pouvons calculer la somme du carré (valeur positives et négatives) des résidus par:
ou de manière équivalente à
Le but bien évidemment est d’avoir cette somme des résidus la plus petite possible. Nous devons donc minimiser RSS
L’approche des moindres carrés choisit \(\beta_0\) et \(\beta_0\) pour minimiser le RSS. On peut montrer que;
où \(\bar{y}=\frac{1}{n}\sum_{i=1}^ny_i\) et\(\bar{x}=\frac{1}{n}\sum_{i=1}^nx_i\) sont les moyennes d’échantillonnage. En d’autres termes, (3.4.1) et (3.4.2) définissent les estimations des coefficients des moindres carrés pour la régression linéaire simple.
Soit le vecteur de paramètres \(\beta\); $\( \beta:=[\beta_0, \dots \beta_1]^T, \)$
le vecteur de la variable réponse des données d’entraînement:
et la matrice contenant les prédicteurs de l’ensemble des données d’entraînement:
\begin{equation*} \mathbf{X}{n,p} = \begin{pmatrix} 1 & x{1,1} & \cdots & x_{1,p} \ 1 & x_{2,1} & \cdots & x_{2,p} \ \vdots & \vdots & \ddots & \vdots \ 1 & x_{n,1} & \cdots & x_{n,p} \end{pmatrix} \end{equation*}
Montrer que l’estimateur OLS ( ordinary least square ) des paramètres \(\beta\) dans une régression linéaire est donné par:
À l’aide du code suivant, nous pouvons créer une fonction de régression de base appelée reg(), qui prend un paramètre y et un paramètre x, et renvoie un vecteur de coefficients bêta estimés :
reg <- function(y, x) {
x <- as.matrix(x)
x <- cbind(Intercept = 1, x)
b <- solve(t(x) %*% x) %*% t(x) %*% y
colnames(b) <- "estimate"
print(b)
}
data <- read.table('https://raw.githubusercontent.com/nmeraihi/data/master/01a_data.txt', as.is=T, header=T)
head(data)
| Name | Team | Position | Height | Weight | Age | |
|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <int> | <int> | <dbl> | |
| 1 | Adam_Donachie | BAL | Catcher | 74 | 180 | 22.99 |
| 2 | Paul_Bako | BAL | Catcher | 74 | 215 | 34.69 |
| 3 | Ramon_Hernandez | BAL | Catcher | 72 | 210 | 30.78 |
| 4 | Kevin_Millar | BAL | First_Baseman | 72 | 210 | 35.43 |
| 5 | Chris_Gomez | BAL | First_Baseman | 73 | 188 | 35.71 |
| 6 | Brian_Roberts | BAL | Second_Baseman | 69 | 176 | 29.39 |
x=data$Height
y=data$Weight
X <- cbind(1, x)
beta_hat <- solve( t(X) %*% X ) %*% t(X) %*% y
beta_hat
| -154.224210 | |
| x | 4.829768 |
fit <- lm(y ~ x);
fit
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-154.22 4.83
reg(y,x)
estimate
Intercept -154.224210
4.829768