
Les jointures de tables partie_1#
Lorsque nous voulons avoir une vue d’ensemble des informations contenues dans plusieurs tables, nous ferons alors joindre ces tables afin d’assembler toute l’information dans une table ou une vue (view).
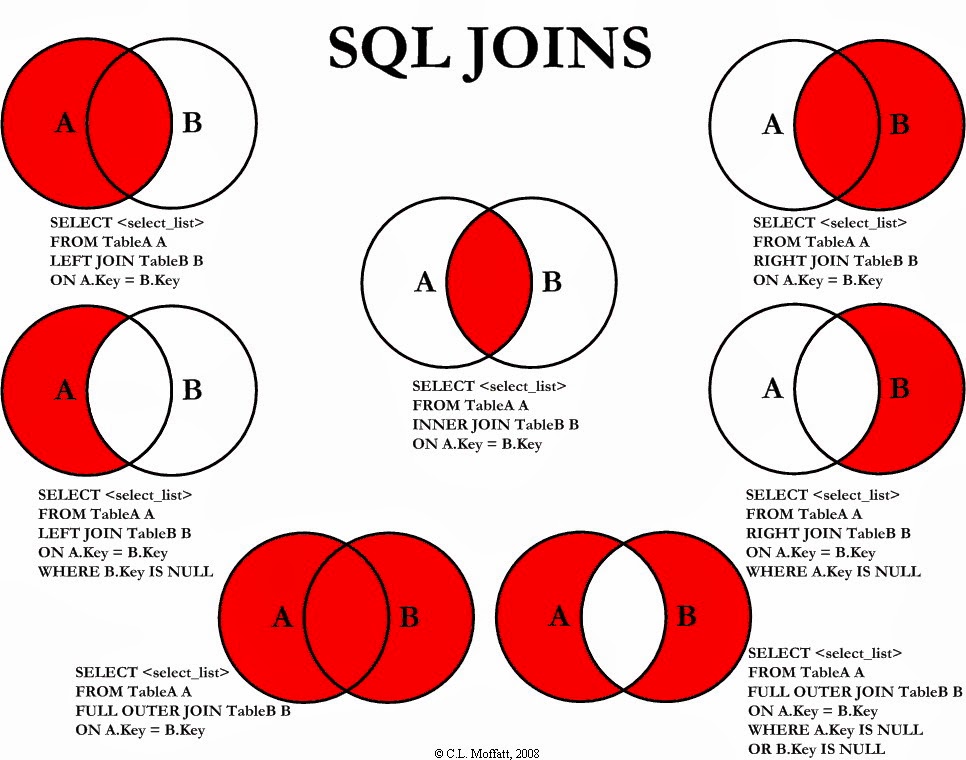
Afin de mieux comprendre la jointure de table, créons deux tables A et B.
proc sql;
create table sql.A
(X num,
Y num);
insert into sql.A
values(1,2)
values(2,3);
quit;
111 ods listing close;ods html5 file=stdout options(bitmap_mode='inline') device=png; ods graphics on / outputfmt=png;
NOTE: Writing HTML5 Body file: STDOUT
112
113 proc sql;
114 create table sql.A
115 (X num,
116 Y num);
NOTE: Table SQL.A created, with 0 rows and 2 columns.
117 insert into sql.A
118 values(1,2)
119 values(2,3);
NOTE: 2 rows were inserted into SQL.A.
120 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.02 seconds
cpu time 0.02 seconds
121 ods html5 close;ods listing;
122
Aperçu de la table A
proc sql;
select *
from sql.A;
quit;
| X | Y |
|---|---|
| 1 | 2 |
| 2 | 3 |
proc sql;
create table sql.B
(X num,
Y num);
insert into sql.B
values(2,5)
values(3,6)
values(4,9);
select *
from sql.B;
quit;
| X | Y |
|---|---|
| 2 | 5 |
| 3 | 6 |
| 4 | 9 |
Aperçu de la table B
proc sql;
select *
from sql.B;
quit;
| X | Y |
|---|---|
| 2 | 5 |
| 3 | 6 |
| 4 | 9 |
Produit cartésien#
La manière la plus simple de joindre deux tables et de relier chaque ligne de la table A avec les lignes de la table B avec la clause from sql.A, sql.B. Ceci donne un produit cartésien tel qu’illustré ci-dessous.
proc sql;
title 'produit cartésien de la table A et de la table B';
select *
from sql.A, sql.B;
quit;
| X | Y | X | Y |
|---|---|---|---|
| 1 | 2 | 2 | 5 |
| 1 | 2 | 3 | 6 |
| 1 | 2 | 4 | 9 |
| 2 | 3 | 2 | 5 |
| 2 | 3 | 3 | 6 |
| 2 | 3 | 4 | 9 |
Inner join avec Where#
Lorsque nous voulons le sous-ensemble de lignes de la première table qui correspond aux lignes de la deuxième table, nous appliquons alors un inner join où (jointure interne). Nous pouvons spécifier les colonnes que nous souhaitons comparer pour les valeurs correspondantes dans une clause WHERE.
proc sql;
title 'Inner Join';
select * from sql.A, sql.B
where A.x=B.x;
| X | Y | X | Y |
|---|---|---|---|
| 2 | 3 | 2 | 5 |
Utilisation d’alias de table#
Un alias de table est un nom temporaire et alternatif pour une table. Nous spécifions les alias de table dans la clause FROM. Les alias de table sont utilisés dans les jointures pour qualifier les noms de colonnes et peuvent rendre une requête plus facile à lire en abréviation des noms de table.
Soit la table oilprod qui provient du livre de référence Ronald P. Cody.
proc sql outobs=5;
select * from libSql.donnes_demo
quit;
| name | province | company | langue | date_naissance | agee | age_permis | numeropol |
|---|---|---|---|---|---|---|---|
| Shane Robinson | Nova Scotia | May Ltd | fr | 1944-10-20 | 72 | 24 | 1 |
| Courtney Nguyen | Saskatchewan | Foley, Moore and Mitchell | en | 1985-12-09 | 31 | 24 | 5 |
| Lori Washington | Yukon Territory | Robinson-Reyes | fr | 1970-01-27 | 47 | 28 | 13 |
| Sarah Castillo | Alberta | Wood, Brady and English | fr | 2000-08-23 | 16 | 16 | 16 |
| Jeffrey Garcia | Nunavut | Berger-Thompson | en | 1969-10-25 | 47 | 20 | 22 |
proc sql outobs=6;
title ' apperçu de la table oilprod';
select * from sql.oilprod
quit;
| Country | BarrelsPerDay |
|---|---|
| Algeria | 1,400,000 |
| Canada | 2,500,000 |
| China | 3,000,000 |
| Egypt | 900,000 |
| Indonesia | 1,500,000 |
| Iran | 4,000,000 |
Soit la table oilrsrvs
proc sql outobs=6;
title ' apperçu de la table oilrsrvs';
select * from sql.oilrsrvs
quit;
| Country | Barrels |
|---|---|
| Algeria | 9,200,000,000 |
| Canada | 7,000,000,000 |
| China | 25,000,000,000 |
| Egypt | 4,000,000,000 |
| Gabon | 1,000,000,000 |
| Indonesia | 5,000,000,000 |
On voudrait maintenant avoir un aperçu des deux tables dans une seule table (ou en créer une toute nouvelle avec une jointure).
Nous donnons un alias o à la table oilprod . Nous écrivons alors sql.oilprod as o
Lorsque nous écrivons la clause where o.country = r.country;, il devient plus facile de comprendre que nous voulons extraire les données où valeurs de la colonne country de la table oilprod alias o sont égaux aux valeurs de la colonne country de la table oilrsrvs alias r
proc sql outobs=6;
title 'Production et réserves de pétrole par pays';
select * from sql.oilprod as o, sql.oilrsrvs as r
where o.country = r.country;
quit;
| Country | BarrelsPerDay | Country | Barrels |
|---|---|---|---|
| Algeria | 1,400,000 | Algeria | 9,200,000,000 |
| Canada | 2,500,000 | Canada | 7,000,000,000 |
| China | 3,000,000 | China | 25,000,000,000 |
| Egypt | 900,000 | Egypt | 4,000,000,000 |
| Indonesia | 1,500,000 | Indonesia | 5,000,000,000 |
| Iran | 4,000,000 | Iran | 90,000,000,000 |
Affichage#
Dans l’exemple précédent, il s’affiche deux colonnes Country, nous pouvons spécifier ce qui s’affiche. Nous pouvons préciser quelles colonnes afficher et dans quel format ou titre.
Dans l’exemple ci-dessous, nous voulons seulement trois colonnes:
p.country affiché avec sous le label pays
p.barrelsperday affiché avec sous le label Production
r.barrels affiché avec sous le label “Réserves”
proc sql outobs=6;
title 'La production et les réserves du pétrole par pays';
select p.country 'Pays', p.barrelsperday 'Production', r.barrels 'Réserves' /* ici nous affichons seulement la co*/
from sql.oilprod p, sql.oilrsrvs r
where p.country = r.country
order by barrelsperday desc;
quit;
title;
| Pays | Production | Réserves |
|---|---|---|
| Saudi Arabia | 9,000,000 | 260,000,000,000 |
| United States of America | 8,000,000 | 30,000,000,000 |
| Iran | 4,000,000 | 90,000,000,000 |
| Norway | 3,500,000 | 11,000,000,000 |
| Mexico | 3,400,000 | 50,000,000,000 |
| China | 3,000,000 | 25,000,000,000 |
Inner join avec On#
Les mots-clés INNER JOIN peuvent être utilisés pour rejoindre des tables. La clause ON remplace la clause WHERE pour spécifier les colonnes à joindre. PROC SQL fournit ces mots-clés principalement pour la compatibilité avec les autres jointures (OUTER, DROITE et GAUCHE JOIN). L’utilisation de INNER JOIN avec une clause ON fournit la même fonctionnalité que la liste des tableaux dans la clause FROM et la spécification des colonnes de jointure avec une clause WHERE.
proc sql outobs=6;
select p.country 'Pays', barrelsperday 'Production', barrels 'Réserves'
from sql.oilprod p inner join sql.oilrsrvs r
on p.country = r.country
order by barrelsperday desc;
quit;
| Pays | Production | Réserves |
|---|---|---|
| Saudi Arabia | 9,000,000 | 260,000,000,000 |
| United States of America | 8,000,000 | 30,000,000,000 |
| Iran | 4,000,000 | 90,000,000,000 |
| Norway | 3,500,000 | 11,000,000,000 |
| Mexico | 3,400,000 | 50,000,000,000 |
| China | 3,000,000 | 25,000,000,000 |
Création des tables;#
Comme nous venons de le faire dans les exemples précédents, nous pouvons créer une table avec CREATE TABLE. Nous nous pouvons spécifier le nom de la colonne, le type, le nombre maximal de caractères à y insérer, le format et le l’étiquette (label)
proc sql;
create table sql.l_data
(Key char(12), Veggies char(12));
insert into sql.l_data
values("Mon","Broccoli")
values("Tue","Celery")
values("Thu","Lettuce")
values("Fri","Spinach");
select *
from sql.l_data;
quit;
| Key | Veggies |
|---|---|
| Mon | Broccoli |
| Tue | Celery |
| Thu | Lettuce |
| Fri | Spinach |
Regardez bien votre répertoire de librairies !, vous allez trouver un fichier sous le nom l_data.sas7bdat
La colonne Key peut avoir le label qu’on voudrait.
proc sql;
create table sql.l_data2
(Key char(12) label='étiquette de clonne détaillé', Veggies char(12));
insert into sql.l_data2
values("Mon","Broccoli")
values("Tue","Celery")
values("Thu","Lettuce")
values("Fri","Spinach");
select *
from sql.l_data2;
quit;
| étiquette de clonne détaillé | Veggies |
|---|---|
| Mon | Broccoli |
| Tue | Celery |
| Thu | Lettuce |
| Fri | Spinach |
Toutefois, remarquez que ce n’est qu’un lable. le nom de la première colonne de la table l_data2 reste toujours Key. Donc si nous voudrions faire des jointures avec d’autres tables, il faut faire attention de bien spécifier le nom de la colonne et nom le label
voici la preuve:
proc sql;
select Key
from sql.l_data2;
quit;
| étiquette de clonne détaillé |
|---|
| Mon |
| Tue |
| Thu |
| Fri |
Un autre exemple de création de la table r_data que nous utiliserons plus tard.
proc sql;
create table sql.r_data
(Key char(12), Fruits char(12));
insert into sql.r_data
values("Mon","Apples")
values("Wed","Dates")
values("Thu","Cherries")
values("Sat","Bananas");
select *
from sql.r_data;
quit;
| Key | Fruits |
|---|---|
| Mon | Apples |
| Wed | Dates |
| Thu | Cherries |
| Sat | Bananas |
Modification des tables#
Ajouter des nouvelles observations#
avec SET#
Des fois, il est très commode de créer une copie vide d’une table que nous avons déjà afin de la modifier à sa guise ou pour d’autres besoins particuliers.
Créons une table semblable à la table sql.countries. Mais d’abord, regardons son contenu.
proc sql outobs=5;
select *
from sql.countries;
quit;
| Name | Capital | Population | Area | Continent | UNDate |
|---|---|---|---|---|---|
| Afghanistan | Kabul | 17070323 | 251825 | Asia | 1946 |
| Albania | Tirane | 3407400 | 11100 | Europe | 1955 |
| Algeria | Algiers | 28171132 | 919595 | Africa | 1962 |
| Andorra | Andorra la Vella | 64634 | 200 | Europe | 1993 |
| Angola | Luanda | 9901050 | 481300 | Africa | 1976 |
Nous créons une table avec la clause create table
proc sql outobs=5;
create table sql.copie_countries
like sql.countries;
quit;
415 ods listing close;ods html5 file=stdout options(bitmap_mode='inline') device=png; ods graphics on / outputfmt=png;
NOTE: Writing HTML5 Body file: STDOUT
416
417 proc sql outobs=5;
418 create table sql.copie_countries
419 like sql.countries;
NOTE: Table SQL.COPIE_COUNTRIES created, with 0 rows and 6 columns.
420 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.01 seconds
cpu time 0.01 seconds
421 ods html5 close;ods listing;
422
Regardons ce que cette table contient;
proc sql;
select Name, Population from sql.copie_countries;
quit;
Évidemment, elle est vide, car nous avons utilisé la clause like à la ligne 4 qui veut seulement dire de prendre le format
Inserer des nouvelles lignes avec la clause Select#
Maintenant supposons que nous voulons insérer dans notre nouvelle table copie_countries les données des pays qui ont une population plus grande ou égale à 130000000 provenant de la table countries
proc sql ;
insert into sql.copie_countries
select * from sql.countries
where population ge 130000000;
quit;
460 ods listing close;ods html5 file=stdout options(bitmap_mode='inline') device=png; ods graphics on / outputfmt=png;
NOTE: Writing HTML5 Body file: STDOUT
461
462 proc sql ;
463 insert into sql.copie_countries
464 select * from sql.countries
465 where population ge 130000000;
NOTE: 6 rows were inserted into SQL.COPIE_COUNTRIES.
466 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.00 seconds
cpu time 0.00 seconds
467 ods html5 close;ods listing;
468
Affichons le résultat;
proc sql;
select * from sql.copie_countries;
quit;
| Name | Capital | Population | Area | Continent | UNDate |
|---|---|---|---|---|---|
| Brazil | Brasilia | 1.6031E8 | 3286500 | South America | 1945 |
| China | Beijing | 1.2022E9 | 3696100 | Asia | 1945 |
| India | New Delhi | 9.2901E8 | 1222600 | Asia | 1945 |
| Indonesia | Jakarta | 2.0239E8 | 741100 | Asia | 1950 |
| Russia | Moscow | 1.5109E8 | 6592800 | Europe | 1945 |
| United States | Washington | 2.6329E8 | 3787318 | North America | 1945 |
| Brazil | Brasilia | 1.6031E8 | 3286500 | South America | 1945 |
| China | Beijing | 1.2022E9 | 3696100 | Asia | 1945 |
| India | New Delhi | 9.2901E8 | 1222600 | Asia | 1945 |
| Indonesia | Jakarta | 2.0239E8 | 741100 | Asia | 1950 |
| Russia | Moscow | 1.5109E8 | 6592800 | Europe | 1945 |
| United States | Washington | 2.6329E8 | 3787318 | North America | 1945 |
Affichons seulement le nom du pays, sa capitale et la population sous le format souhaité.
proc sql;
select name format=$20.,
capital format=$15.,
population format=comma15.0
from sql.copie_countries;
quit;
| Name | Capital | Population |
|---|---|---|
| Brazil | Brasilia | 160,310,357 |
| China | Beijing | 1,202,215,077 |
| India | New Delhi | 929,009,120 |
| Indonesia | Jakarta | 202,393,859 |
| Russia | Moscow | 151,089,979 |
| United States | Washington | 263,294,808 |
| Brazil | Brasilia | 160,310,357 |
| China | Beijing | 1,202,215,077 |
| India | New Delhi | 929,009,120 |
| Indonesia | Jakarta | 202,393,859 |
| Russia | Moscow | 151,089,979 |
| United States | Washington | 263,294,808 |
| Bangladesh | Dhaka | 126,391,060 |
| Japan | Tokyo | 126,352,003 |
Insérer des nouvelles lignes avec la clause SET#
Maintenant, regardons comment insérer de nouvelles observations ou de nouvelles lignes entrées manuellement. On peut faire ceci avec la clause Set.
proc sql;
insert into sql.copie_countries
set name='Bangladesh',
capital='Dhaka',
population=126391060
set name='Japan',
capital='Tokyo',
population=126352003;
quit;
486 ods listing close;ods html5 file=stdout options(bitmap_mode='inline') device=png; ods graphics on / outputfmt=png;
NOTE: Writing HTML5 Body file: STDOUT
487
488 proc sql;
489 insert into sql.copie_countries
490 set name='Bangladesh',
491 capital='Dhaka',
492 population=126391060
493 set name='Japan',
494 capital='Tokyo',
495 population=126352003;
NOTE: 2 rows were inserted into SQL.COPIE_COUNTRIES.
496 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.00 seconds
cpu time 0.01 seconds
497 ods html5 close;ods listing;
498
Regardons ce que ça donne:
proc sql;
select name format=$20.,
capital format=$15.,
population format=comma15.0
from sql.copie_countries;
quit;
| Name | Capital | Population |
|---|---|---|
| Brazil | Brasilia | 160,310,357 |
| China | Beijing | 1,202,215,077 |
| India | New Delhi | 929,009,120 |
| Indonesia | Jakarta | 202,393,859 |
| Russia | Moscow | 151,089,979 |
| United States | Washington | 263,294,808 |
| Brazil | Brasilia | 160,310,357 |
| China | Beijing | 1,202,215,077 |
| India | New Delhi | 929,009,120 |
| Indonesia | Jakarta | 202,393,859 |
| Russia | Moscow | 151,089,979 |
| United States | Washington | 263,294,808 |
| Bangladesh | Dhaka | 126,391,060 |
| Japan | Tokyo | 126,352,003 |
Nous remarquons que les deux nouvelles observations Bangladesh et Japan sont maintenant dans notre table copie_countries
Aficchage avec SELECT from (select )#
reprenons l’exemple où nous avons affiché la production et les réserves du pétrole par pays via une jointure de deux tables (oilprod et oilrsrvs)
proc sql ;
select p.country 'Pays', barrelsperday 'Production', barrels 'Réserves'
from sql.oilprod p, sql.oilrsrvs r
where p.country = r.country
order by barrelsperday desc;
quit;
| Pays | Production | Réserves |
|---|---|---|
| Saudi Arabia | 9,000,000 | 260,000,000,000 |
| United States of America | 8,000,000 | 30,000,000,000 |
| Iran | 4,000,000 | 90,000,000,000 |
| Norway | 3,500,000 | 11,000,000,000 |
| Mexico | 3,400,000 | 50,000,000,000 |
| China | 3,000,000 | 25,000,000,000 |
| United Kingdom | 3,000,000 | 4,500,000,000 |
| Venezuela | 3,000,000 | 65,000,000,000 |
| Canada | 2,500,000 | 7,000,000,000 |
| Kuwait | 2,500,000 | 95,000,000,000 |
| United Arab Emirates | 2,000,000 | 100,000,000 |
| Nigeria | 2,000,000 | 16,000,000,000 |
| Indonesia | 1,500,000 | 5,000,000,000 |
| Libya | 1,500,000 | 30,000,000,000 |
| Algeria | 1,400,000 | 9,200,000,000 |
| Egypt | 900,000 | 4,000,000,000 |
| Iraq | 600,000 | 110,000,000,000 |
Supposons qu’à partir du tableau précédent, nous voulons avoir seulement les pays avec une production de 3000000 barils par jour.
proc sql ;
select * from
/***************************************************/
/* Ici on joint les deux tables*/
(select p.country 'Pays', p.barrelsperday 'Production', r.barrels 'Réserves'
from sql.oilprod p, sql.oilrsrvs r
where p.country = r.country
) as table_resultante
/***************************************************/
where table_resultante.BarrelsPerDay >= 3000000
;
quit;
| Pays | Production | Réserves |
|---|---|---|
| China | 3,000,000 | 25,000,000,000 |
| Iran | 4,000,000 | 90,000,000,000 |
| Mexico | 3,400,000 | 50,000,000,000 |
| Norway | 3,500,000 | 11,000,000,000 |
| Saudi Arabia | 9,000,000 | 260,000,000,000 |
| United Kingdom | 3,000,000 | 4,500,000,000 |
| United States of America | 8,000,000 | 30,000,000,000 |
| Venezuela | 3,000,000 | 65,000,000,000 |
Remarquez qu’à la dernière ligne, nous avons écrit where table_resultante.BarrelsPerDay >= 3000000, et non table_resultante.Production. Nous avons défini “Production” comme label et non comme nom de colonne.
proc sql ;
select * from
/***************************************************/
/* Ici on joint les deux tables*/
(select p.country as Pays, p.barrelsperday as Production, r.barrels as Reserve
from sql.oilprod p, sql.oilrsrvs r
where p.country = r.country
) as table_resultante
/***************************************************/
where table_resultante.Production >= 3000000
/*même si on ne spécifie pas l'alis table_resultante.'*/
/*where Production >= 3000000*/
;
quit;
| Pays | Production | Reserve |
|---|---|---|
| China | 3,000,000 | 25,000,000,000 |
| Iran | 4,000,000 | 90,000,000,000 |
| Mexico | 3,400,000 | 50,000,000,000 |
| Norway | 3,500,000 | 11,000,000,000 |
| Saudi Arabia | 9,000,000 | 260,000,000,000 |
| United Kingdom | 3,000,000 | 4,500,000,000 |
| United States of America | 8,000,000 | 30,000,000,000 |
| Venezuela | 3,000,000 | 65,000,000,000 |
proc sql ;
select * from
/***************************************************/
/* Ici on joint les deux tables*/
(select p.country as Pays, p.barrelsperday as Production, r.barrels as Reserve
from sql.oilprod p, sql.oilrsrvs r
where p.country = r.country
) as table_resultante
/***************************************************/
/*même si on ne spécifie pas l'alis table_resultante.'*/
where Production >= 3000000
;
quit;
| Pays | Production | Reserve |
|---|---|---|
| China | 3,000,000 | 25,000,000,000 |
| Iran | 4,000,000 | 90,000,000,000 |
| Mexico | 3,400,000 | 50,000,000,000 |
| Norway | 3,500,000 | 11,000,000,000 |
| Saudi Arabia | 9,000,000 | 260,000,000,000 |
| United Kingdom | 3,000,000 | 4,500,000,000 |
| United States of America | 8,000,000 | 30,000,000,000 |
| Venezuela | 3,000,000 | 65,000,000,000 |
Un autre exemple où l’on voudrait extraire les noms de pays et leurs populations qui ont une population plus grande que celle de la Belgique:
Si on savait exactement quelle est la population de la Belgique, on aurait écrit ceci;
proc sql;
title 'U.S. States with Population Greater than Belgium';
select Name 'State', population format=comma10.
from sql.unitedstates
where population gt 10162614;
quit;
| State | Population |
|---|---|
| California | 31,518,948 |
| Florida | 13,814,408 |
| Illinois | 11,813,091 |
| New York | 18,377,334 |
| Ohio | 11,200,790 |
| Pennsylvania | 12,167,566 |
| Texas | 18,209,994 |
Supposons que nous ignorons ce nombre, nous avons qu’à extraire ce chiffre avec un Select
(select population from sql.countries
where name = "Belgium");
Ensuite, nous appliquons notre condition where sur ce résultat
where population gt
(select population from sql.countries
where name = "Belgium");
proc sql;
title 'les pays plus populeux que la Belgique';
select Name 'State' , population format=comma10.
from sql.unitedstates
where population gt
(select population from sql.countries
where name = "Belgium");
quit;
titel;
| State | Population |
|---|---|
| California | 31,518,948 |
| Florida | 13,814,408 |
| Illinois | 11,813,091 |
| New York | 18,377,334 |
| Ohio | 11,200,790 |
| Pennsylvania | 12,167,566 |
| Texas | 18,209,994 |
proc sql;
title 'les pays plus populeux que la Belgique';
select Name 'State' , population format=comma10.
from sql.unitedstates
where population gt
(select population from sql.countries
where name = "Belgium");
quit;
titel;
%macro genExpoLambda(population, lambda,graine,NomDataSet);
proc sql;
title 'les pays plus populeux que la Belgique';
select Name 'State' , population format=comma10.
from sql.unitedstates
where &population gt
(select population from sql.countries
where name = "Belgium");
quit;
titel;
%mend genExpoLambda;
Cette façon de faire est très utile lorsque nos données varient souvent dans le temps et que nous ne savons jamais la valeur exacte de la condition. Par exemple une banque qui veut savoir les comptes des commerçants ayant plus que 100k$ dans le compte à un moment donné.