
Les jointures de tables partie_2#
Dans cette partie du cours, nous allons appliquer les procédures proc sql que nous avons apprises, sur une base de données relationnelle d’assurance automobile. Il faut noter que ces données proviennent d’une vraie bd d’assurance. Toutefois, le contenu a été modifié et plusieurs variables ont été supprimées à des fins de confidentialité. Nous avons gardé l’essentiel des données qui nous servent de matériel pédagogique pour les cours d’actuariat à l’UQAM.
Analysons d’abord l’architecture de cette base de données présentée ci-dessous:
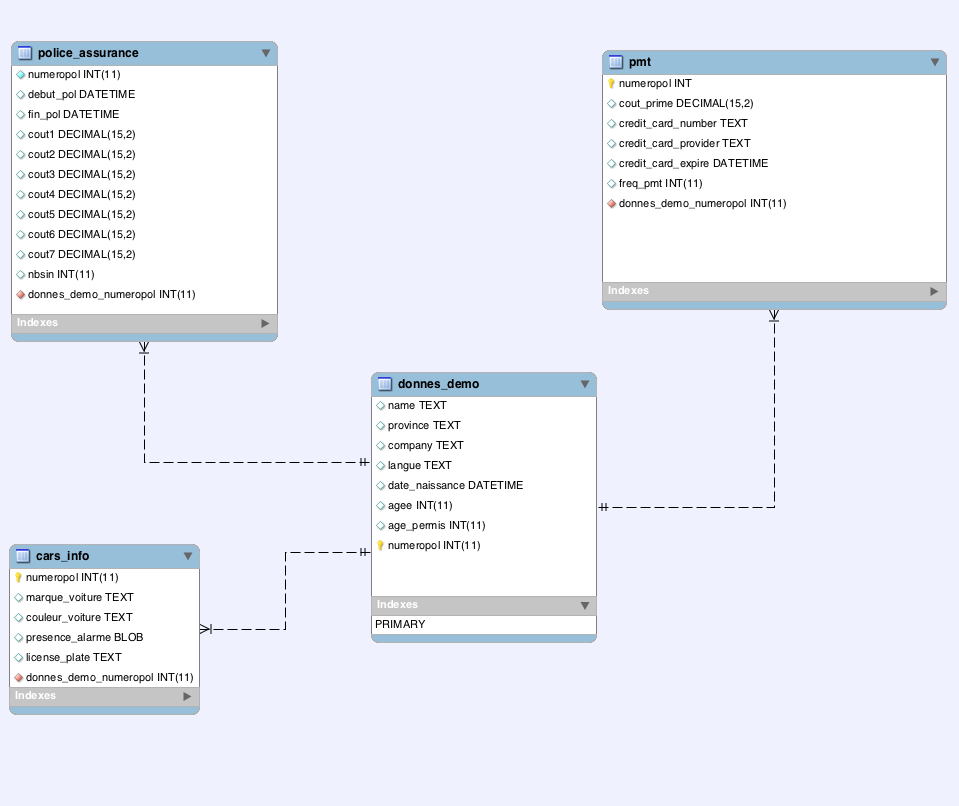
On voit bien que nous avons essentiellement quatre tables avec lesquelles nous allons travailler;
Tout d’abord, la table
donnes_demodans laquelle nous trouvons les informations démographiques des assurés. Cette table contient une clé primaire (colonne « numeropol ») qui est le numéro de police de l’assuré. C’est avec cette colonne (attribut dans le langagesql) qui permet de relier les quatre tables entre elles.Ensuite, nous avons la table
police_assurancequi nous donne l’information sur chaque police d’assuranceLa table
pmtnous donne l’information sur les primes payées par les assurés, comme le montant, le mode de paiement …etc.Enfin, la table
cars_ifonous donne l’information sur les véhicules au dossier de l’assuré.
Analysons l’aperçu sur chacune des tables;
libname bdSQL "data/bdsql";
title "Apperçu de la table donnes_demo";
proc sql outobs=5;
select * from bdSQL.donnes_demo
quit;
| name | province | company | langue | date_naissance | agee | age_permis | numeropol |
|---|---|---|---|---|---|---|---|
| Shane Robinson | Nova Scotia | May Ltd | fr | 1944-10-20 | 72 | 24 | 1 |
| Courtney Nguyen | Saskatchewan | Foley, Moore and Mitchell | en | 1985-12-09 | 31 | 24 | 5 |
| Lori Washington | Yukon Territory | Robinson-Reyes | fr | 1970-01-27 | 47 | 28 | 13 |
| Sarah Castillo | Alberta | Wood, Brady and English | fr | 2000-08-23 | 16 | 16 | 16 |
| Jeffrey Garcia | Nunavut | Berger-Thompson | en | 1969-10-25 | 47 | 20 | 22 |
title "Apperçu de la table police_assurance";
proc sql outobs=5;
select * from bdSQL.police_assurance
quit;
| numeropol | debut_pol | fin_pol | cout1 | cout2 | cout3 | cout4 | cout5 | cout6 | cout7 | nbsin |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1999-11-10 | 2000-10-16 | . | . | . | . | . | . | . | 0 |
| 1 | 2000-10-17 | 2000-11-09 | . | . | . | . | . | . | . | 0 |
| 1 | 2000-11-10 | 2001-11-09 | 243.85714286 | . | . | . | . | . | . | 1 |
| 5 | 1996-01-03 | 1996-03-27 | . | . | . | . | . | . | . | 0 |
| 5 | 1996-03-28 | 1997-01-02 | . | . | . | . | . | . | . | 0 |
title "Apperçu de la table pmt";
proc sql outobs=5;
select * from bdSQL.pmt
quit;
| numeropol | cout_prime | credit_card_number | credit_card_provider | credit_card_expire | freq_pmt |
|---|---|---|---|---|---|
| 1 | 1060.28 | 4.4274761E15 | Voyager | 01APR23:00:00:00 | 12 |
| 5 | 1200.89 | 5.3033891E15 | JCB 16 digit | 01AUG26:00:00:00 | 1 |
| 13 | 940.54 | 3.5285692E15 | Maestro | 01AUG22:00:00:00 | 12 |
| 16 | 860.75 | 6.0115698E15 | VISA 13 digit | 01MAR23:00:00:00 | 1 |
| 22 | 790.17 | 5.2624946E15 | Maestro | 01AUG20:00:00:00 | 1 |
title "Apperçu de la table cars_info";
proc sql outobs=5;
select * from bdSQL.cars_info
quit;
| numeropol | marque_voiture | couleur_voiture | presence_alarme | license_plate |
|---|---|---|---|---|
| 1 | Autres | Autre | 0 | DW 3168 |
| 5 | RENAULT | Autre | 0 | 926 1RL |
| 13 | RENAULT | Autre | 1 | SOV 828 |
| 16 | HONDA | Autre | 0 | ENSK 514 |
| 22 | VOLKSWAGEN | Autre | 1 | 453 CFM |
Maintenant que nous avons eu connaissance de notre base de données, on peut remarquer que la table police_assurance peut contenir plusieurs informations pour un même assuré, alors que les autres tables en contiennent qu’une seule ligne par assuré. En effet, les tables peuvent avoir différentes relations qu’on appelle:
On to one
On to many
many to many
Étudions plus en détail les deux premières
On To One#
Lorsque nous avons deux tables où il existe une seule observation pour un id donné, nous avons alors une relation de type One to one. Cette situation s’illustre bien avec les deux tables donnes_demo, et pmt. Dans les deux tables nous avons une seule observation par id.. Les deux tables peuvent être relié par le id de l’assuré.
Si nous cherchons par exemple le fournisseur de carte de crédit de chaque assuré;
title "Type de carte de crédit pour chaque assuré";
proc sql outobs=5;
select a.name, b.credit_card_provider
from bdSQL.donnes_demo as a left join bdSQL.pmt as b
on a.numeropol = b.numeropol
;
quit;
| name | credit_card_provider |
|---|---|
| Shane Robinson | Voyager |
| Courtney Nguyen | JCB 16 digit |
| Lori Washington | Maestro |
| Sarah Castillo | VISA 13 digit |
| Jeffrey Garcia | Maestro |
Si nous avions voulu faire cette opération avec un data step, nous aurons fait ceci:
proc sort data = bdSQL.donnes_demo;
by numeropol;
run;
proc sort data = bdSQL.pmt;
by numeropol;
run;
data bdSQL.Data_step_one2one ;
merge bdSQL.donnes_demo(in = left) bdSQL.pmt(in = right);
by numeropol;
if left;
keep name credit_card_provider;
run;
proc print data=bdSQL.Data_step_one2one (obs=5) noobs;
run;
| name | credit_card_provider |
|---|---|
| Shane Robinson | Voyager |
| Courtney Nguyen | JCB 16 digit |
| Lori Washington | Maestro |
| Sarah Castillo | VISA 13 digit |
| Jeffrey Garcia | Maestro |
On remarque que c’est beaucoup plus simple d’utiliser les procédures sql quand il s’agit de telles situations
One To Many#
Lorsque nous avons une table avec un seul identifiant pour chaque observation (assuré), et une autre table où chaque assuré peut avoir plus qu’une observation (donc un même id qui se répète sur plus qu’une ligne), nous somme alors en présence de relation entre deux tables de type On To Many. Par exemple;
title "Nombte de sinistre total par assuré";
proc sql outobs=5;
select a.name, sum(b.nbsin) as nombreSin
from bdSQL.donnes_demo as a left join bdSQL.police_assurance as b
on a.numeropol = b.numeropol
group by a.name
order by nombreSin desc
;
quit;
| name | nombreSin |
|---|---|
| Betty Scott | 11 |
| Dustin Banks | 10 |
| Angela Smith | 9 |
| Jimmy Harrison | 8 |
| Aaron Tucker | 8 |
Si nous cherchons la liste des noms de tous les assurés et le nombre de sinistres total qu’ils ont eus. Il faut noter que nous cherchons le total du nombre de sinistres de chaque assuré sachant qu’un assuré donné peut avoir zéro ou plus qu’un sinistre.
Remarquez que cela aurait pu bien fonctionner en utilisant right à la place de left
title "Nombte de sinistre total par assuré";
proc sql outobs=5;
select a.name, sum(b.nbsin) as nombreSin
from bdSQL.donnes_demo as a right join bdSQL.police_assurance as b
on a.numeropol = b.numeropol
group by a.name
order by nombreSin desc
;
quit;
| name | nombreSin |
|---|---|
| Betty Scott | 11 |
| Dustin Banks | 10 |
| Angela Smith | 9 |
| Jimmy Harrison | 8 |
| Aaron Tucker | 8 |
ou
title "Nombre de sinistre total par assuré";
proc sql outobs=5;
select b.name, sum(a.nbsin) as nombreSin
from bdSQL.police_assurance as a right join bdSQL.donnes_demo as b
on a.numeropol = b.numeropol
group by b.name
order by nombreSin desc
;
quit;
| name | nombreSin |
|---|---|
| Betty Scott | 11 |
| Dustin Banks | 10 |
| Angela Smith | 9 |
| Jimmy Harrison | 8 |
| Aaron Tucker | 8 |
Jointure de plus que deux table#
Imaginons que nous voulons créer une table qui nous donne: le nombre de sinistre par province, en plus d’avoir l’information s’il ya présence d’alarme ou pas (o ou 1)
/* petit exercice */
title;
proc sql ;
create table bdSQL.prov_alar_sinis as
select a.province, c.presence_alarme, sum(b.nbsin) as numbSin
from bdSQL.donnes_demo a, bdSQL.police_assurance b , bdSQL.cars_info c
where a.numeropol=b.numeropol and a.numeropol=c.numeropol
group by province, presence_alarme
;
proc sql;
select * from bdSQL.prov_alar_sinis;
quit;
| province | presence_alarme | numbSin |
|---|---|---|
| Alberta | 0 | 527 |
| Alberta | 1 | 481 |
| British Columbia | 0 | 483 |
| British Columbia | 1 | 501 |
| Manitoba | 0 | 435 |
| Manitoba | 1 | 444 |
| New Brunswick | 0 | 996 |
| New Brunswick | 1 | 991 |
| Newfoundland and Labrador | 0 | 526 |
| Newfoundland and Labrador | 1 | 484 |
| Northwest Territories | 0 | 464 |
| Northwest Territories | 1 | 458 |
| Nova Scotia | 0 | 457 |
| Nova Scotia | 1 | 442 |
| Nunavut | 0 | 426 |
| Nunavut | 1 | 517 |
| Ontario | 0 | 523 |
| Ontario | 1 | 428 |
| Prince Edward Island | 0 | 459 |
| Prince Edward Island | 1 | 430 |
| Quebec | 0 | 431 |
| Quebec | 1 | 425 |
| Saskatchewan | 0 | 506 |
| Saskatchewan | 1 | 461 |
| Yukon Territory | 0 | 489 |
| Yukon Territory | 1 | 473 |
Mettre à jour une table#
Avec les procédures proc sql, ils aussi possible de modifier les tables telles que l’ajout d’observations, en supprimer d’autres …etc.
Supposons que nous créerons une nouvelle table où nous avons le nombre total de sinistres, le coût total par province, pour les assurés ayant une alarme ou pas pour chacune des provinces.
/* petit exercice */
title;
proc sql ;
create table bdSQL.prov_alar_sinis as
select a.province, c.presence_alarme, sum(b.nbsin) as numbSin, sum(d.cout_prime) as coutTot format=dollar15.2
from bdSQL.donnes_demo a, bdSQL.police_assurance b , bdSQL.cars_info c, bdSQL.pmt d
where a.numeropol=b.numeropol and a.numeropol=c.numeropol and a.numeropol=d.numeropol
group by province, presence_alarme
;
proc sql;
select * from bdSQL.prov_alar_sinis;
quit;
| province | presence_alarme | numbSin | coutTot |
|---|---|---|---|
| Alberta | 0 | 527 | $1,810,648.26 |
| Alberta | 1 | 481 | $2,159,837.70 |
| British Columbia | 0 | 483 | $1,845,870.63 |
| British Columbia | 1 | 501 | $2,251,772.80 |
| Manitoba | 0 | 435 | $1,816,059.04 |
| Manitoba | 1 | 444 | $2,052,799.22 |
| New Brunswick | 0 | 996 | $4,063,876.55 |
| New Brunswick | 1 | 991 | $4,910,546.77 |
| Newfoundland and Labrador | 0 | 526 | $2,114,873.41 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 |
| Northwest Territories | 0 | 464 | $1,831,869.64 |
| Northwest Territories | 1 | 458 | $2,303,249.95 |
| Nova Scotia | 0 | 457 | $1,863,869.16 |
| Nova Scotia | 1 | 442 | $2,140,654.70 |
| Nunavut | 0 | 426 | $1,767,940.35 |
| Nunavut | 1 | 517 | $2,299,574.47 |
| Ontario | 0 | 523 | $1,869,489.94 |
| Ontario | 1 | 428 | $2,198,819.46 |
| Prince Edward Island | 0 | 459 | $1,823,033.74 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 |
| Quebec | 0 | 431 | $1,791,020.49 |
| Quebec | 1 | 425 | $2,099,646.42 |
| Saskatchewan | 0 | 506 | $2,078,543.11 |
| Saskatchewan | 1 | 461 | $2,380,597.45 |
| Yukon Territory | 0 | 489 | $2,090,626.75 |
| Yukon Territory | 1 | 473 | $2,271,767.28 |
Maintenant, supposons que nous voulons augmenter les coûts des primes par 2% pour tous les assurés n’ayant pas une alarme installée sur le véhicule. Mais d’abord, créons une copie de la table prov_alar_sinis qu’on appellera prov_alar_sinis2 afin d’y apporter de modifications
proc sql;
create table bdSQL.prov_alar_sinis2 like bdSQL.prov_alar_sinis;
insert into bdSQL.prov_alar_sinis2
select * from bdSQL.prov_alar_sinis;
select * from bdSQL.prov_alar_sinis2;
quit;
| province | presence_alarme | numbSin | coutTot |
|---|---|---|---|
| Alberta | 0 | 527 | $1,810,648.26 |
| Alberta | 1 | 481 | $2,159,837.70 |
| British Columbia | 0 | 483 | $1,845,870.63 |
| British Columbia | 1 | 501 | $2,251,772.80 |
| Manitoba | 0 | 435 | $1,816,059.04 |
| Manitoba | 1 | 444 | $2,052,799.22 |
| New Brunswick | 0 | 996 | $4,063,876.55 |
| New Brunswick | 1 | 991 | $4,910,546.77 |
| Newfoundland and Labrador | 0 | 526 | $2,114,873.41 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 |
| Northwest Territories | 0 | 464 | $1,831,869.64 |
| Northwest Territories | 1 | 458 | $2,303,249.95 |
| Nova Scotia | 0 | 457 | $1,863,869.16 |
| Nova Scotia | 1 | 442 | $2,140,654.70 |
| Nunavut | 0 | 426 | $1,767,940.35 |
| Nunavut | 1 | 517 | $2,299,574.47 |
| Ontario | 0 | 523 | $1,869,489.94 |
| Ontario | 1 | 428 | $2,198,819.46 |
| Prince Edward Island | 0 | 459 | $1,823,033.74 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 |
| Quebec | 0 | 431 | $1,791,020.49 |
| Quebec | 1 | 425 | $2,099,646.42 |
| Saskatchewan | 0 | 506 | $2,078,543.11 |
| Saskatchewan | 1 | 461 | $2,380,597.45 |
| Yukon Territory | 0 | 489 | $2,090,626.75 |
| Yukon Territory | 1 | 473 | $2,271,767.28 |
Appliquons maintenant l’augmentation de 2%
proc sql;
update bdSQL.prov_alar_sinis2
set coutTot=coutTot*1.02
where presence_alarme=0;
title "Selectively Updated presence_alarme Values";
select *
from bdSQL.prov_alar_sinis2;
quit;
| province | presence_alarme | numbSin | coutTot |
|---|---|---|---|
| Alberta | 0 | 527 | $1,846,861.23 |
| Alberta | 1 | 481 | $2,159,837.70 |
| British Columbia | 0 | 483 | $1,882,788.04 |
| British Columbia | 1 | 501 | $2,251,772.80 |
| Manitoba | 0 | 435 | $1,852,380.22 |
| Manitoba | 1 | 444 | $2,052,799.22 |
| New Brunswick | 0 | 996 | $4,145,154.08 |
| New Brunswick | 1 | 991 | $4,910,546.77 |
| Newfoundland and Labrador | 0 | 526 | $2,157,170.88 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 |
| Northwest Territories | 0 | 464 | $1,868,507.03 |
| Northwest Territories | 1 | 458 | $2,303,249.95 |
| Nova Scotia | 0 | 457 | $1,901,146.54 |
| Nova Scotia | 1 | 442 | $2,140,654.70 |
| Nunavut | 0 | 426 | $1,803,299.16 |
| Nunavut | 1 | 517 | $2,299,574.47 |
| Ontario | 0 | 523 | $1,906,879.74 |
| Ontario | 1 | 428 | $2,198,819.46 |
| Prince Edward Island | 0 | 459 | $1,859,494.41 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 |
| Quebec | 0 | 431 | $1,826,840.90 |
| Quebec | 1 | 425 | $2,099,646.42 |
| Saskatchewan | 0 | 506 | $2,120,113.97 |
| Saskatchewan | 1 | 461 | $2,380,597.45 |
| Yukon Territory | 0 | 489 | $2,132,439.28 |
| Yukon Territory | 1 | 473 | $2,271,767.28 |
Supprimer des observations#
Afin d’en faire un exemple seulement, sans aucune pensée politique quelconque, supposons que nous voulons séparer les données sur le Qéubec du reste des autres provinces. Donc, nous aurons deux tables, celle qui contient les informations sur les Québec, et l’autre contient les informations des autres provinces.
proc sql;
create table bdSQL.Quebec like bdSQL.prov_alar_sinis;
insert into bdSQL.Quebec
select * from bdSQL.prov_alar_sinis
where province like 'Q%';
select * from bdSQL.Quebec;
quit;
| province | presence_alarme | numbSin | coutTot |
|---|---|---|---|
| Quebec | 0 | 431 | $1,826,840.90 |
| Quebec | 1 | 425 | $2,099,646.42 |
Supprimons maintenant les données du Québec de notre table principale
proc sql;
delete
from bdSQL.prov_alar_sinis
where province like 'Q%';
select * from bdSQL.prov_alar_sinis;
quit;
| province | presence_alarme | numbSin | coutTot |
|---|---|---|---|
| Alberta | 0 | 527 | $1,846,861.23 |
| Alberta | 1 | 481 | $2,159,837.70 |
| British Columbia | 0 | 483 | $1,882,788.04 |
| British Columbia | 1 | 501 | $2,251,772.80 |
| Manitoba | 0 | 435 | $1,852,380.22 |
| Manitoba | 1 | 444 | $2,052,799.22 |
| New Brunswick | 0 | 996 | $4,145,154.08 |
| New Brunswick | 1 | 991 | $4,910,546.77 |
| Newfoundland and Labrador | 0 | 526 | $2,157,170.88 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 |
| Northwest Territories | 0 | 464 | $1,868,507.03 |
| Northwest Territories | 1 | 458 | $2,303,249.95 |
| Nova Scotia | 0 | 457 | $1,901,146.54 |
| Nova Scotia | 1 | 442 | $2,140,654.70 |
| Nunavut | 0 | 426 | $1,803,299.16 |
| Nunavut | 1 | 517 | $2,299,574.47 |
| Ontario | 0 | 523 | $1,906,879.74 |
| Ontario | 1 | 428 | $2,198,819.46 |
| Prince Edward Island | 0 | 459 | $1,859,494.41 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 |
| Saskatchewan | 0 | 506 | $2,120,113.97 |
| Saskatchewan | 1 | 461 | $2,380,597.45 |
| Yukon Territory | 0 | 489 | $2,132,439.28 |
| Yukon Territory | 1 | 473 | $2,271,767.28 |
Ajout d’une colonne#
Supposons qu’on veut ajouter une colonne qui serait simplement le coût par sinistre:
proc sql;
alter table bdSQL.prov_alar_sinis
add cout_par_sinsn num label='Coût par sinistre' format=dollar15.2;
update bdSQL.prov_alar_sinis
set cout_par_sinsn=coutTot/numbSin;
select *
from bdSQL.prov_alar_sinis;
quit;
| province | presence_alarme | numbSin | coutTot | Coût par sinistre |
|---|---|---|---|---|
| Alberta | 0 | 527 | $1,846,861.23 | $3,504.48 |
| Alberta | 1 | 481 | $2,159,837.70 | $4,490.31 |
| British Columbia | 0 | 483 | $1,882,788.04 | $3,898.11 |
| British Columbia | 1 | 501 | $2,251,772.80 | $4,494.56 |
| Manitoba | 0 | 435 | $1,852,380.22 | $4,258.35 |
| Manitoba | 1 | 444 | $2,052,799.22 | $4,623.42 |
| New Brunswick | 0 | 996 | $4,145,154.08 | $4,161.80 |
| New Brunswick | 1 | 991 | $4,910,546.77 | $4,955.14 |
| Newfoundland and Labrador | 0 | 526 | $2,157,170.88 | $4,101.09 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 | $5,314.88 |
| Northwest Territories | 0 | 464 | $1,868,507.03 | $4,026.95 |
| Northwest Territories | 1 | 458 | $2,303,249.95 | $5,028.93 |
| Nova Scotia | 0 | 457 | $1,901,146.54 | $4,160.06 |
| Nova Scotia | 1 | 442 | $2,140,654.70 | $4,843.11 |
| Nunavut | 0 | 426 | $1,803,299.16 | $4,233.10 |
| Nunavut | 1 | 517 | $2,299,574.47 | $4,447.92 |
| Ontario | 0 | 523 | $1,906,879.74 | $3,646.04 |
| Ontario | 1 | 428 | $2,198,819.46 | $5,137.43 |
| Prince Edward Island | 0 | 459 | $1,859,494.41 | $4,051.19 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 | $5,353.50 |
| Saskatchewan | 0 | 506 | $2,120,113.97 | $4,189.95 |
| Saskatchewan | 1 | 461 | $2,380,597.45 | $5,163.99 |
| Yukon Territory | 0 | 489 | $2,132,439.28 | $4,360.82 |
| Yukon Territory | 1 | 473 | $2,271,767.28 | $4,802.89 |
On peut aussi modifier le format, le label ou la largeur d’une colonne avec l’option MODIFY. Par exemple, notre nouvelle colonne cout_par_sinsn qui avait un format dollar=15.2, on peut réduire le format à dollar=19.0
proc sql;
alter table bdSQL.prov_alar_sinis
modify cout_par_sinsn format=dollar10.0;
select * from bdSQL.prov_alar_sinis;
quit;
| province | presence_alarme | numbSin | coutTot | Coût par sinistre |
|---|---|---|---|---|
| Alberta | 0 | 527 | $1,846,861.23 | $3,504 |
| Alberta | 1 | 481 | $2,159,837.70 | $4,490 |
| British Columbia | 0 | 483 | $1,882,788.04 | $3,898 |
| British Columbia | 1 | 501 | $2,251,772.80 | $4,495 |
| Manitoba | 0 | 435 | $1,852,380.22 | $4,258 |
| Manitoba | 1 | 444 | $2,052,799.22 | $4,623 |
| New Brunswick | 0 | 996 | $4,145,154.08 | $4,162 |
| New Brunswick | 1 | 991 | $4,910,546.77 | $4,955 |
| Newfoundland and Labrador | 0 | 526 | $2,157,170.88 | $4,101 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 | $5,315 |
| Northwest Territories | 0 | 464 | $1,868,507.03 | $4,027 |
| Northwest Territories | 1 | 458 | $2,303,249.95 | $5,029 |
| Nova Scotia | 0 | 457 | $1,901,146.54 | $4,160 |
| Nova Scotia | 1 | 442 | $2,140,654.70 | $4,843 |
| Nunavut | 0 | 426 | $1,803,299.16 | $4,233 |
| Nunavut | 1 | 517 | $2,299,574.47 | $4,448 |
| Ontario | 0 | 523 | $1,906,879.74 | $3,646 |
| Ontario | 1 | 428 | $2,198,819.46 | $5,137 |
| Prince Edward Island | 0 | 459 | $1,859,494.41 | $4,051 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 | $5,353 |
| Saskatchewan | 0 | 506 | $2,120,113.97 | $4,190 |
| Saskatchewan | 1 | 461 | $2,380,597.45 | $5,164 |
| Yukon Territory | 0 | 489 | $2,132,439.28 | $4,361 |
| Yukon Territory | 1 | 473 | $2,271,767.28 | $4,803 |
Supprimer une colonne:#
La clause DROP permet de supprimer une colonne d’une table donnée;
proc sql;
alter table bdSQL.prov_alar_sinis
drop cout_par_sinsn;
select * from bdSQL.prov_alar_sinis;
quit;
| province | presence_alarme | numbSin | coutTot |
|---|---|---|---|
| Alberta | 0 | 527 | $1,846,861.23 |
| Alberta | 1 | 481 | $2,159,837.70 |
| British Columbia | 0 | 483 | $1,882,788.04 |
| British Columbia | 1 | 501 | $2,251,772.80 |
| Manitoba | 0 | 435 | $1,852,380.22 |
| Manitoba | 1 | 444 | $2,052,799.22 |
| New Brunswick | 0 | 996 | $4,145,154.08 |
| New Brunswick | 1 | 991 | $4,910,546.77 |
| Newfoundland and Labrador | 0 | 526 | $2,157,170.88 |
| Newfoundland and Labrador | 1 | 484 | $2,572,403.03 |
| Northwest Territories | 0 | 464 | $1,868,507.03 |
| Northwest Territories | 1 | 458 | $2,303,249.95 |
| Nova Scotia | 0 | 457 | $1,901,146.54 |
| Nova Scotia | 1 | 442 | $2,140,654.70 |
| Nunavut | 0 | 426 | $1,803,299.16 |
| Nunavut | 1 | 517 | $2,299,574.47 |
| Ontario | 0 | 523 | $1,906,879.74 |
| Ontario | 1 | 428 | $2,198,819.46 |
| Prince Edward Island | 0 | 459 | $1,859,494.41 |
| Prince Edward Island | 1 | 430 | $2,302,004.23 |
| Saskatchewan | 0 | 506 | $2,120,113.97 |
| Saskatchewan | 1 | 461 | $2,380,597.45 |
| Yukon Territory | 0 | 489 | $2,132,439.28 |
| Yukon Territory | 1 | 473 | $2,271,767.28 |
Supprimer une table!#
Même s’il faut se poser cette question plusieurs fois avant d’exécuter la commande sql, on peut toujours supprimer complètement une table comme ceci:
proc sql;
drop table bdSQL.Quebec;
615 ods listing close;ods html5 (id=saspy_internal) file=stdout options(bitmap_mode='inline') device=svg; ods graphics on /
615! outputfmt=png;
NOTE: Writing HTML5(SASPY_INTERNAL) Body file: STDOUT
616
617 proc sql;
618 drop table bdSQL.Quebec;
NOTE: Table BDSQL.QUEBEC has been dropped.
619
620 ods html5 (id=saspy_internal) close;ods listing;
621
Autres procédures SQL#
Compter le nombre de doublons:#
Compter les doublons est une des premières tâches que vous aurez à faire lorsque vous allez manipuler des bases de données un peu plus importantes
Soit la table doublons
proc sql;
create table bdSQL.doublons
(id char(12), Nom char(12));
insert into bdSQL.doublons
values("123", "Noureddine Meraihi")
values("124", "Gabriel A")
values("125", "JM P")
values("126", "Mathieu P")
values("127", "Mathieu B")
values("126", "Mathieu P")
values("128", "JP B");
select * from bdSQL.doublons;
quit;
| id | Nom |
|---|---|
| 123 | Noureddine M |
| 124 | Gabriel A |
| 125 | JM P |
| 126 | Mathieu P |
| 127 | Mathieu B |
| 126 | Mathieu P |
| 128 | JP B |
proc sql;
title 'Duplicate Rows in Duplicates Table';
select *, count(*) as Count
from bdSQL.doublons
group by id, Nom
having count(*) > 1;
quit;
| id | Nom | Count |
|---|---|---|
| 126 | Mathieu P | 2 |
Ou on peut aussi utiliser la fonction freq afin de trouver le nombre de récurrences
proc freq
data = bdSQL.doublons;
tables Nom / nocum nocol norow nopercent
;
run;
The FREQ Procedure
| Nom | Frequency |
|---|---|
| Gabriel A | 1 |
| JM P | 1 |
| JP B | 1 |
| Mathieu B | 1 |
| Mathieu P | 2 |
| Noureddine M | 1 |
PROC rank#
Cette procédure est très intéressante si vous voulez trouver le rang d’une observation par variable. Dans l’exemple suivant, nous cherchons le rang de chaque candidat aux élections. D’abord, par le nombre de votes. Ensuite, par année.
data elect;
input Candidate $ 1-11 District 13 Vote 15-18 Years 20;
datalines;
Cardella 1 1689 8
Latham 1 1005 2
Smith 1 1406 0
Walker 1 846 0
Hinkley 2 912 0
Kreitemeyer 2 1198 0
Lundell 2 2447 6
Thrash 2 912 2
;
proc rank data=elect out=results ties=low descending;
by district;
var vote years;
ranks VoteRank YearsRank;
run;
proc print data=results n;
by district;
title 'Results of City Council Election';
run;
| Obs | Candidate | Vote | Years | VoteRank | YearsRank |
|---|---|---|---|---|---|
| 1 | Cardella | 1689 | 8 | 1 | 1 |
| 2 | Latham | 1005 | 2 | 3 | 2 |
| 3 | Smith | 1406 | 0 | 2 | 3 |
| 4 | Walker | 846 | 0 | 4 | 3 |
| N = 4 | |||||
| Obs | Candidate | Vote | Years | VoteRank | YearsRank |
|---|---|---|---|---|---|
| 5 | Hinkley | 912 | 0 | 3 | 3 |
| 6 | Kreitemeyer | 1198 | 0 | 2 | 3 |
| 7 | Lundell | 2447 | 6 | 1 | 1 |
| 8 | Thrash | 912 | 2 | 3 | 2 |
| N = 4 | |||||
Compare procedure#
La procédure Compare est aussi intéressante lorsque vous voulez comparer les différences deux variables se trouvant dans deux tables différentes. En voici un exemple où l’on veut comparer la variable coutTot dans les deux tables prov_alar_sinis et prov_alar_sinis2. On se rappelle que dans la deuxième, nous avons augmenté les coûts de primes par 2%, seulement pour les véhicules qui ne sont pas munis d’un système d’alarme.
options nodate pageno=1 linesize=80 pagesize=40;
proc compare base=bdSQL.prov_alar_sinis2 compare=bdSQL.prov_alar_sinis nosummary;
var coutTot;
with coutTot;
title 'Comparison of Variables in Different Data Sets';
run;
The COMPARE Procedure
Comparison of BDSQL.PROV_ALAR_SINIS2 with BDSQL.PROV_ALAR_SINIS
(Method=EXACT)
NOTE: Values of the following 1 variables compare unequal: coutTot^=coutTot
Value Comparison Results for Variables
__________________________________________________________
|| Base Compare
Obs || coutTot coutTot Diff. % Diff
________ || _________ _________ _________ _________
||
1 || 1846861.2 1810648.3 -36213 -1.9608
3 || 1882788.0 1845870.6 -36917 -1.9608
5 || 1852380.2 1816059.0 -36321 -1.9608
7 || 4145154.1 4063876.5 -81278 -1.9608
9 || 2157170.9 2114873.4 -42297 -1.9608
11 || 1868507.0 1831869.6 -36637 -1.9608
13 || 1901146.5 1863869.2 -37277 -1.9608
15 || 1803299.2 1767940.4 -35359 -1.9608
17 || 1906879.7 1869489.9 -37390 -1.9608
19 || 1859494.4 1823033.7 -36461 -1.9608
21 || 1826840.9 1791020.5 -35820 -1.9608
23 || 2120114.0 2078543.1 -41571 -1.9608
25 || 2132439.3 2090626.7 -41813 -1.9608
__________________________________________________________
TRANSPOSE Procedure#
La procédure Transpose peut être très utile lorsque nous voulons transposer nos variables en observation et vice versa. Dans l’exemple suivant, nous avons une liste d’étudiants (observation) avec les notes qu’ils ont eues à trois examens (donc trois variables). On voudrait trois observations (trois lignes) qui représentent Test1, Test2 et Test3. Et sept variables (les 7 étudiants).
options nodate pageno=1 linesize=80 pagesize=40;
data score;
input Student $9. StudentID $ Section $ Test1 Test2 Final;
datalines;
Capalleti 0545 1 94 91 87
Dubose 1252 2 51 65 91
Engles 1167 1 95 97 97
Grant 1230 2 63 75 80
Krupski 2527 2 80 76 71
Lundsford 4860 1 92 40 86
McBane 0674 1 75 78 72
;
proc print data=score noobs;
title 'Données oriiginales';
run;
proc transpose data=score out=score_transposed;
run;
proc print data=score_transposed noobs;
title 'Student Test Scores in Variables';
run;
| Student | StudentID | Section | Test1 | Test2 | Final |
|---|---|---|---|---|---|
| Capalleti | 0545 | 1 | 94 | 91 | 87 |
| Dubose | 1252 | 2 | 51 | 65 | 91 |
| Engles | 1167 | 1 | 95 | 97 | 97 |
| Grant | 1230 | 2 | 63 | 75 | 80 |
| Krupski | 2527 | 2 | 80 | 76 | 71 |
| Lundsford | 4860 | 1 | 92 | 40 | 86 |
| McBane | 0674 | 1 | 75 | 78 | 72 |
| _NAME_ | COL1 | COL2 | COL3 | COL4 | COL5 | COL6 | COL7 |
|---|---|---|---|---|---|---|---|
| Test1 | 94 | 51 | 95 | 63 | 80 | 92 | 75 |
| Test2 | 91 | 65 | 97 | 75 | 76 | 40 | 78 |
| Final | 87 | 91 | 97 | 80 | 71 | 86 | 72 |