
Modèle de Régression Logistique avec SAS#
Dans cette partie, nous aborderons les diverses procédures de SAS comme proc content et proc means, et la façon de construire un modèle de régression logistique pour estimer le risque de défaut de paiement sur des prêts bancaires.
libname biblio "/home/nmeraihi1/A23";
FILENAME REFFILE '/home/nmeraihi1/A23/loan_default_dataset.csv';
PROC IMPORT DATAFILE=REFFILE
DBMS=CSV
OUT=biblio.defaut_pret;
GETNAMES=YES;
RUN;
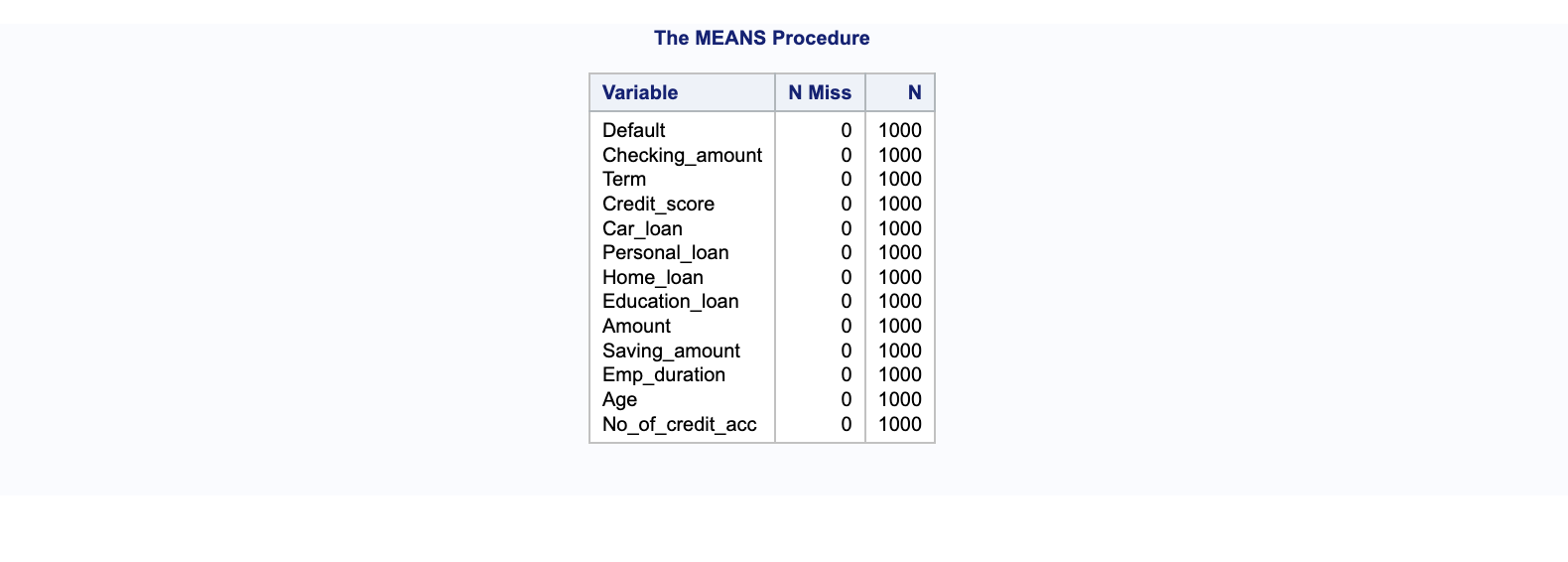
Pour identifier le nombre de valeurs manquantes dans les variables numériques de vos données, NMISS dénombre les observations manquantes et N le nombre d’observations présentes. Par exemple, un résultat de procédure means qui montre 0 pour NMISS indiquerait l’absence de valeurs manquantes dans l’ensemble des données analysées.
* Vérification des valeurs manquantes dans les variables numériques ;
proc means data= biblio.defaut_pret NMISS N;
run;
Exploration du Contenu des Données avec SAS#
Pour examiner en détail le contenu de votre ensemble de données, la procédure PROC CONTENTS est essentielle. Elle permet de lister les informations telles que le nombre d’observations, le nombre de variables, ainsi que les détails de chaque variable, y compris le type (numérique ou caractère), la longueur, le format et l’informat.
* Vérification du contenu des données ;
PROC CONTENTS DATA=biblio.defaut_pret;
RUN;
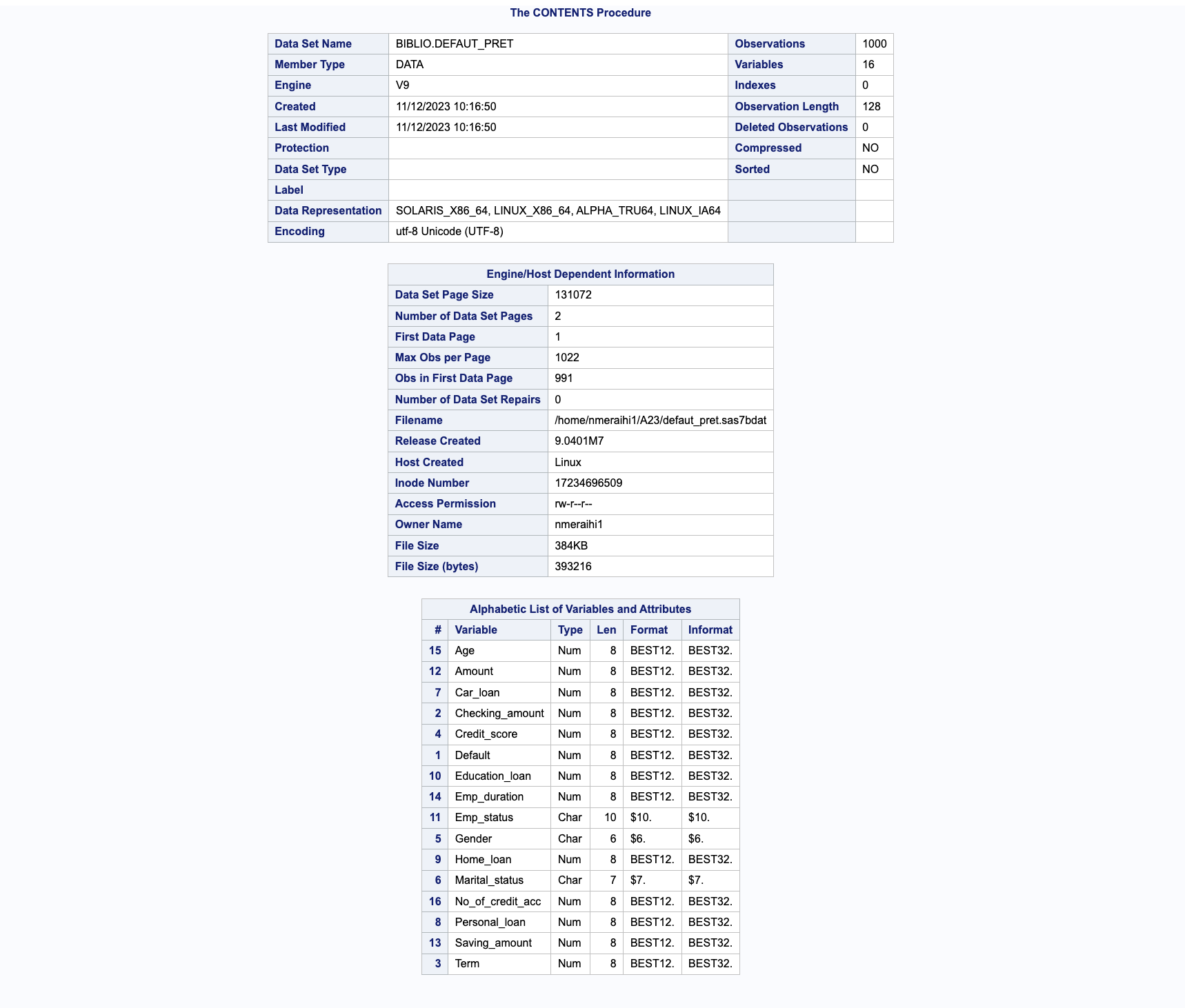
Le résultat de cette procédure sera partiellement affiché dans un tableau, tel qu’illustré dans le tableau ci-dessus, détaillant le contenu de l’ensemble des données. Ce tableau inclura des informations telles que le nombre total d’observations, le nombre de variables, et pour chaque variable, la bibliothèque, le nom, le type de données ainsi que leur longueur, leur format et leur informat si applicable.
Statistiques Descriptives des Données avec SAS#
Pour obtenir un résumé statistique de vos données, la procédure proc means est très utile. Cette commande permet de générer des statistiques descriptives telles que le nombre d’observations, la moyenne, l’écart-type, ainsi que les valeurs minimales et maximales pour des variables spécifiques.
* Statistiques descriptives des données ;
proc means data= biblio.defaut_pret;
var Term Saving_amount;
run;

En exécutant proc means, SAS affichera un tableau récapitulatif pour les variables sélectionnées. Ce tableau présentera le nombre d’observations (N), la moyenne (Mean), l’écart-type (Standard Deviation), ainsi que les valeurs minimales (Min) et maximales (Max) pour chaque variable mentionnée.
Application de Proc Freq pour Analyser la Fréquence des Données avec SAS#
La procédure proc freq est utilisée pour observer la distribution des fréquences des données. Elle fournit des statistiques telles que la fréquence de chaque niveau d’une variable, la fréquence cumulative et le pourcentage cumulatif. Par exemple, elle peut déterminer le nombre de personnes employées, le nombre de personnes sans emploi, le nombre de cas de défaut de paiement (1) et le nombre de non-défaut (0).
* Application de Proc freq pour visualiser la fréquence des données ;
proc freq data = biblio.defaut_pret;
tables Emp_status Default Default*Emp_status;
run;
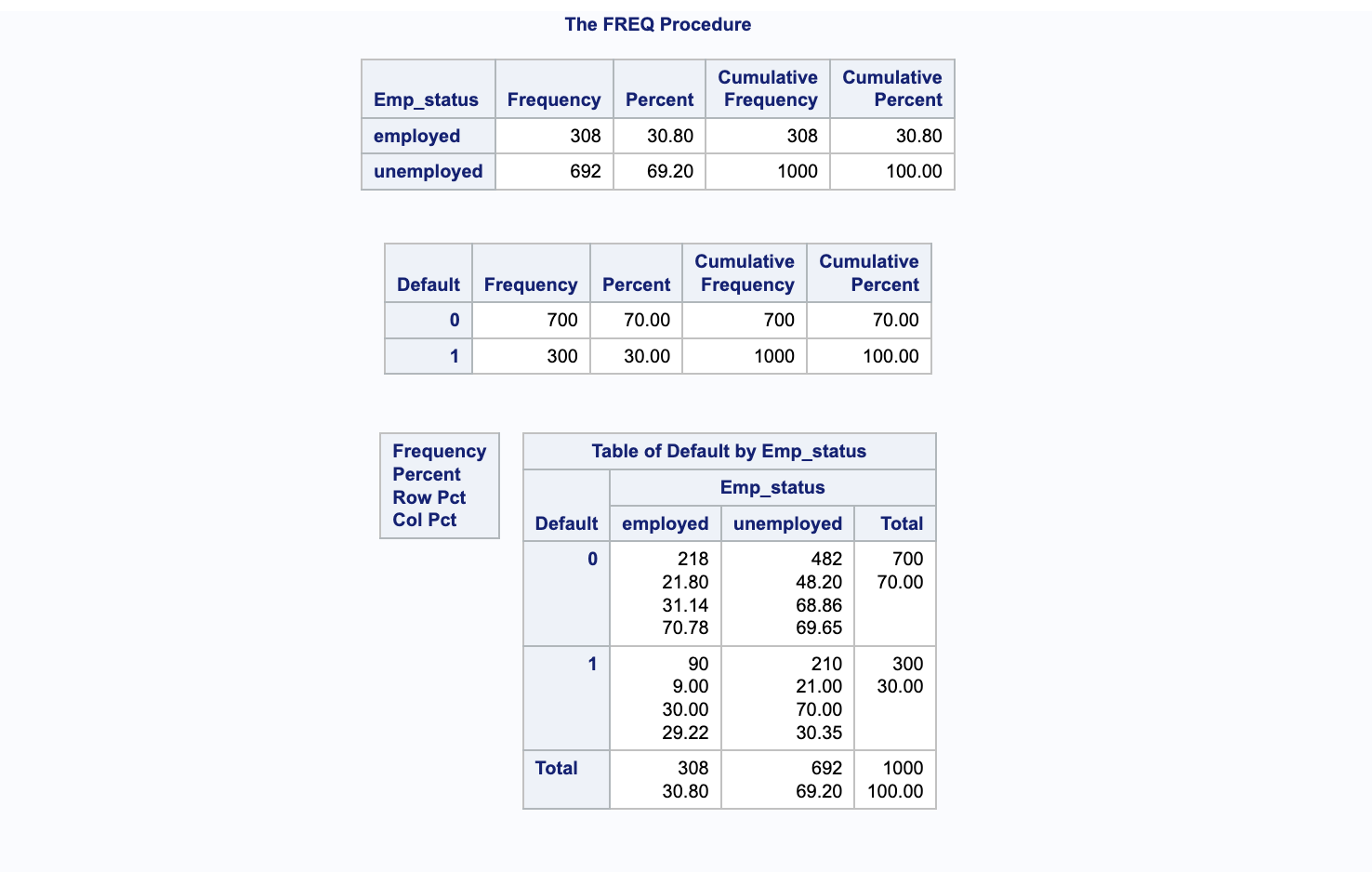
Cette procédure offre un aperçu précis de la répartition des catégories au sein de votre jeu de données, permettant ainsi une meilleure compréhension des caractéristiques des variables analysées.
La procédure proc freq peut aussi être employée pour examiner l’interaction entre deux variables, comme default et Emp_status. Elle permet de générer un tableau croisé qui donne la fréquence, le pourcentage total, le pourcentage par ligne et le pourcentage par colonne pour les croisements des catégories de ces deux variables.
Ce tableau croisé est un outil précieux pour comprendre la relation entre l’état d’emploi et le défaut de paiement dans un jeu de données, offrant des perspectives sur comment une variable peut influencer l’autre
Utilisation de Proc Univariate pour un Résumé Détailé des Données avec SAS#
La procédure proc univariate dans SAS est utilisée pour obtenir un résumé statistique détaillé d’une variable. Elle fournit des statistiques telles que la moyenne, la médiane, l’écart-type, la kurtosis et le skewness. De plus, elle permet de générer des histogrammes pour visualiser la distribution de la variable.
* Application de proc univariate pour un résumé détaillé des données ;
proc univariate data = biblio.defaut_pret;
var Saving_amount;
histogram Saving_amount/normal;
run;
Cette procédure est particulièrement utile pour comprendre la distribution d’une variable continue et pour détecter les anomalies ou les tendances non évidentes dans les données.
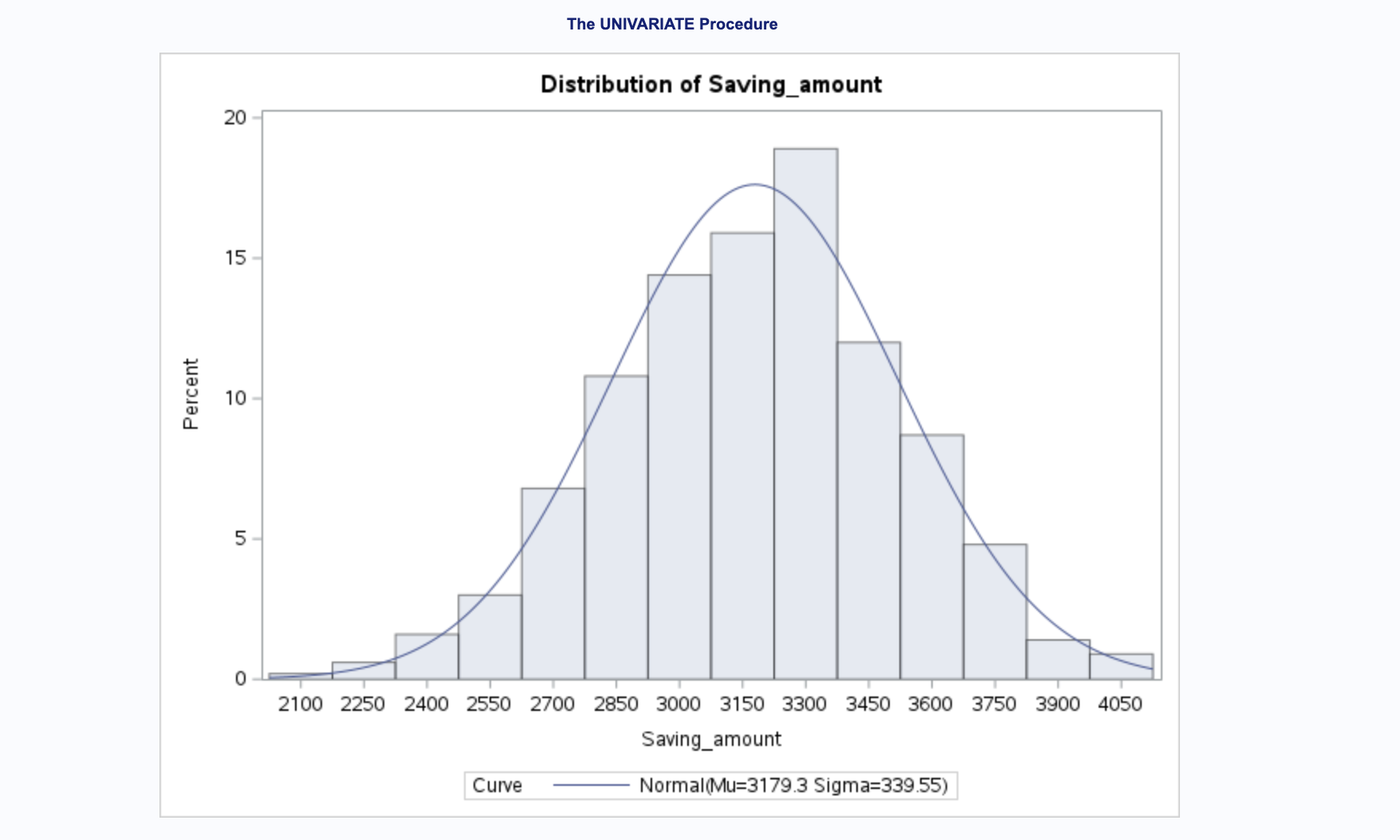
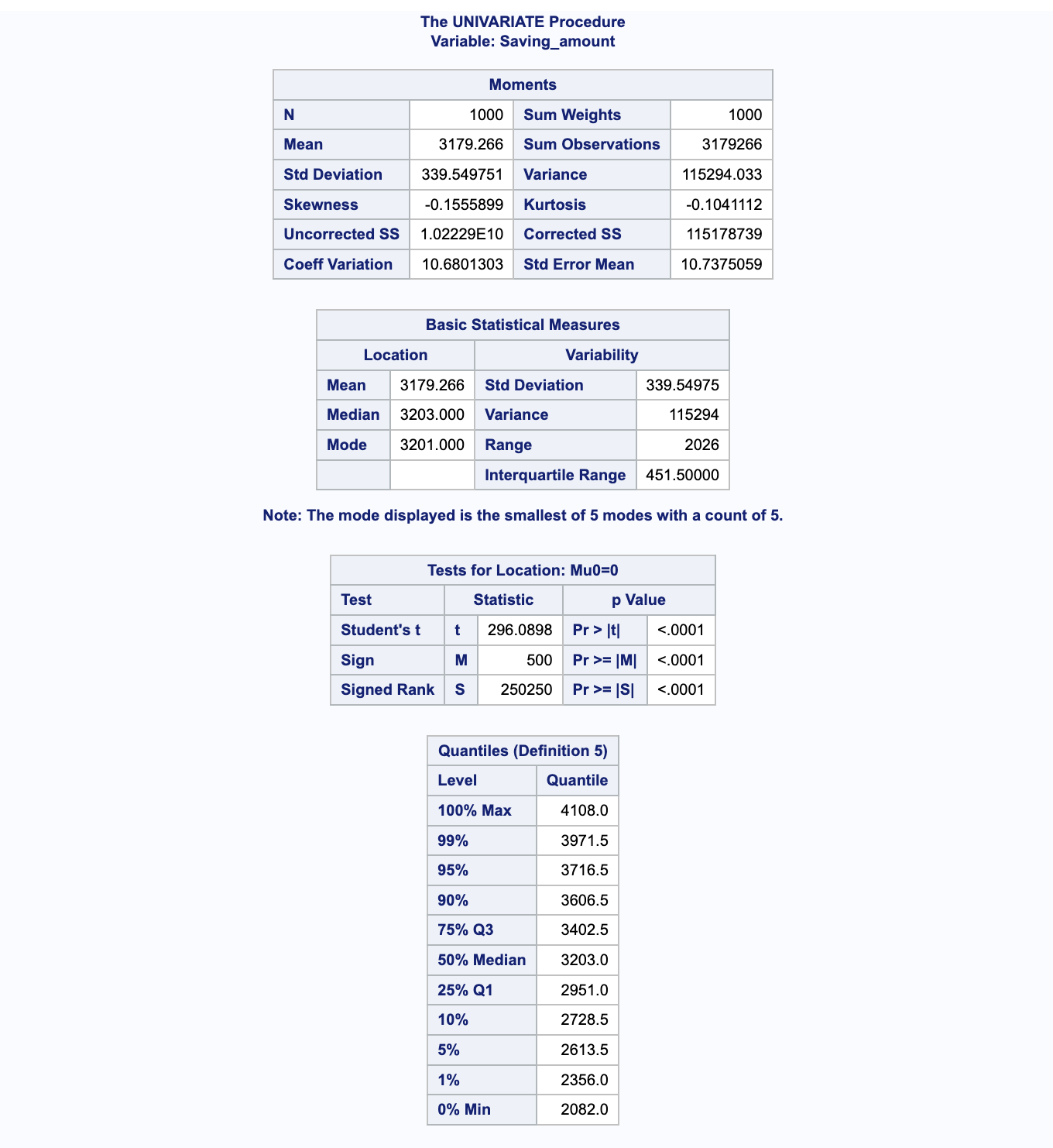
L’histogramme montre la fréquence relative (en pourcentage) de différentes valeurs de la variable Saving_amount. Chaque barre représente un intervalle de montant d’épargne, et la hauteur de la barre indique le pourcentage d’observations dans cet intervalle.
On voit également une courbe de distribution normale est superposée à l’histogramme. Cette courbe est une estimation de la façon dont les données se distribueraient si elles suivaient une distribution normale. Les paramètres de cette courbe normale, la moyenne (Mu) et l’écart-type (Sigma), sont indiqués sur l’histogramme (Mu=3179.3, Sigma=339.55).
Résultats de la Procédure UNIVARIATE pour Saving_amount#
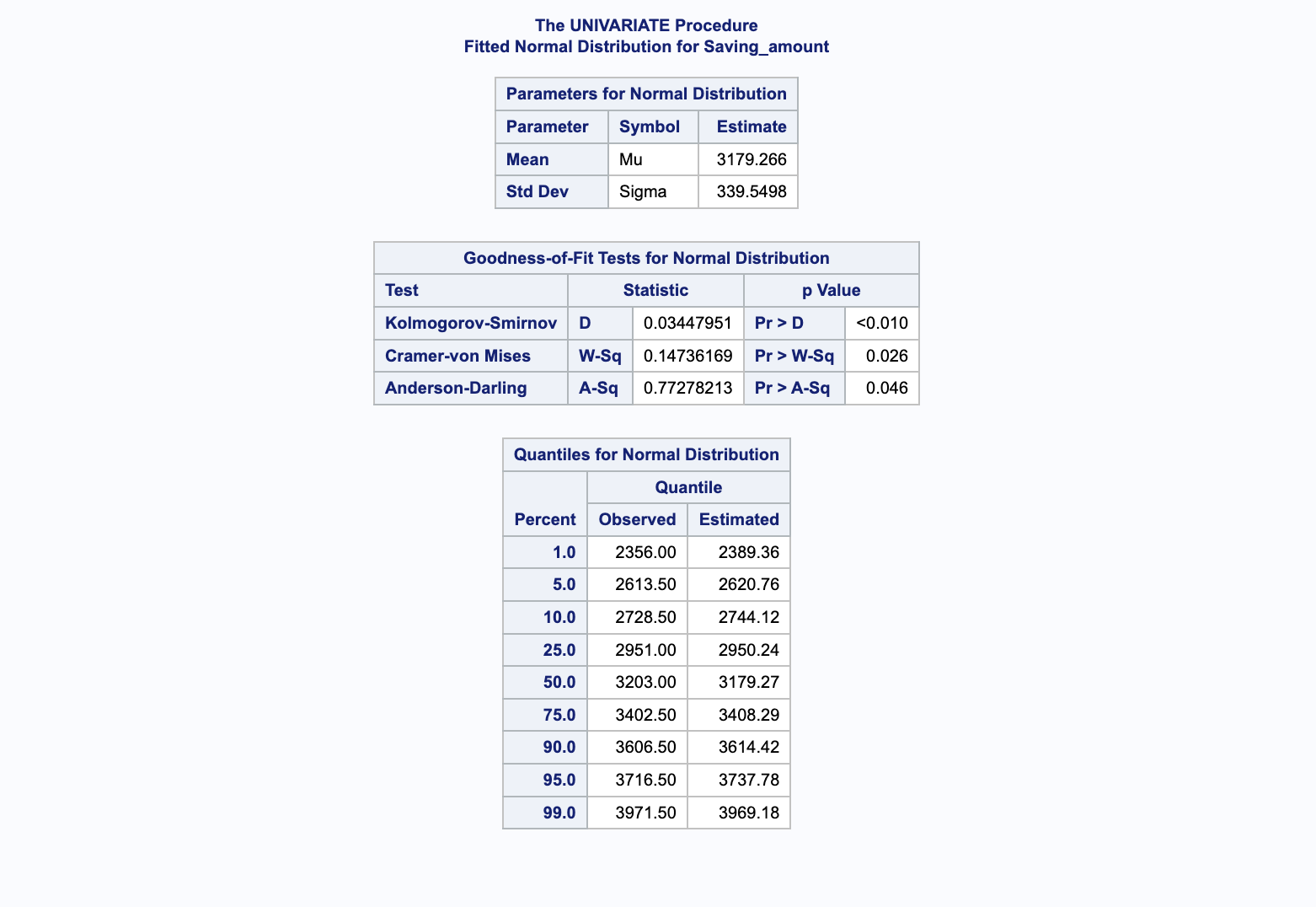
Après avoir exécuté la procédure UNIVARIATE sur la variable Saving_amount, nous obtenons les résultats suivants, qui sont essentiels pour comprendre la distribution des données.
Paramètres de la Distribution Normale Ajustée#
La table des Paramètres pour la Distribution Normale présente les estimations pour la moyenne et l’écart-type :
Moyenne (Mu) : L’estimation de la moyenne est de 3179.266, ce qui suggère que, en moyenne, les montants d’épargne se concentrent autour de cette valeur.
Écart-type (Sigma) : Avec une estimation de l’écart-type à 339.5498, cela reflète la variation des montants d’épargne autour de la moyenne.
Tests de Bonne Adéquation pour la Distribution Normale#
Les tests suivants évaluent si les données suivent une distribution normale :
Kolmogorov-Smirnov (D) : Ce test a une valeur p inférieure à 0.01, indiquant que la distribution des données diffère de manière significative d’une distribution normale.
Cramer-von Mises (W-Sq) et Anderson-Darling (A-Sq) : Ces tests renforcent les résultats du test Kolmogorov-Smirnov, suggérant également des écarts significatifs par rapport à une distribution normale.
Quantiles pour la Distribution Normale#
La section des Quantiles pour la Distribution Normale compare les quantiles observés avec ceux estimés par une distribution normale :
Les colonnes
ObservéetEstiménous montrent comment les quantiles réels des données se comparent à ceux d’une distribution normale théorique. Des écarts importants entre ces valeurs indiquent des différences significatives entre la distribution réelle des données et la distribution normale.
Ces résultats nous fournissent un aperçu détaillé de la nature de la distribution des montants d’épargne et soulignent l’importance de la visualisation et des tests statistiques pour comprendre pleinement les caractéristiques des données analysées.
Exploration de la Corrélation avec proc corr dans SAS#
L’analyse de corrélation est un outil statistique essentiel pour découvrir et quantifier la relation linéaire entre deux variables. En appliquant la procédure proc corr, nous pouvons examiner la corrélation entre les variables dans nos données.
Mise en application#
Voici comment nous appliquons proc corr pour les variables Default et Age :
* Application de proc corr pour découvrir la corrélation entre les variables ;
proc corr data = biblio.defaut_pret;
var Default Age;
run;
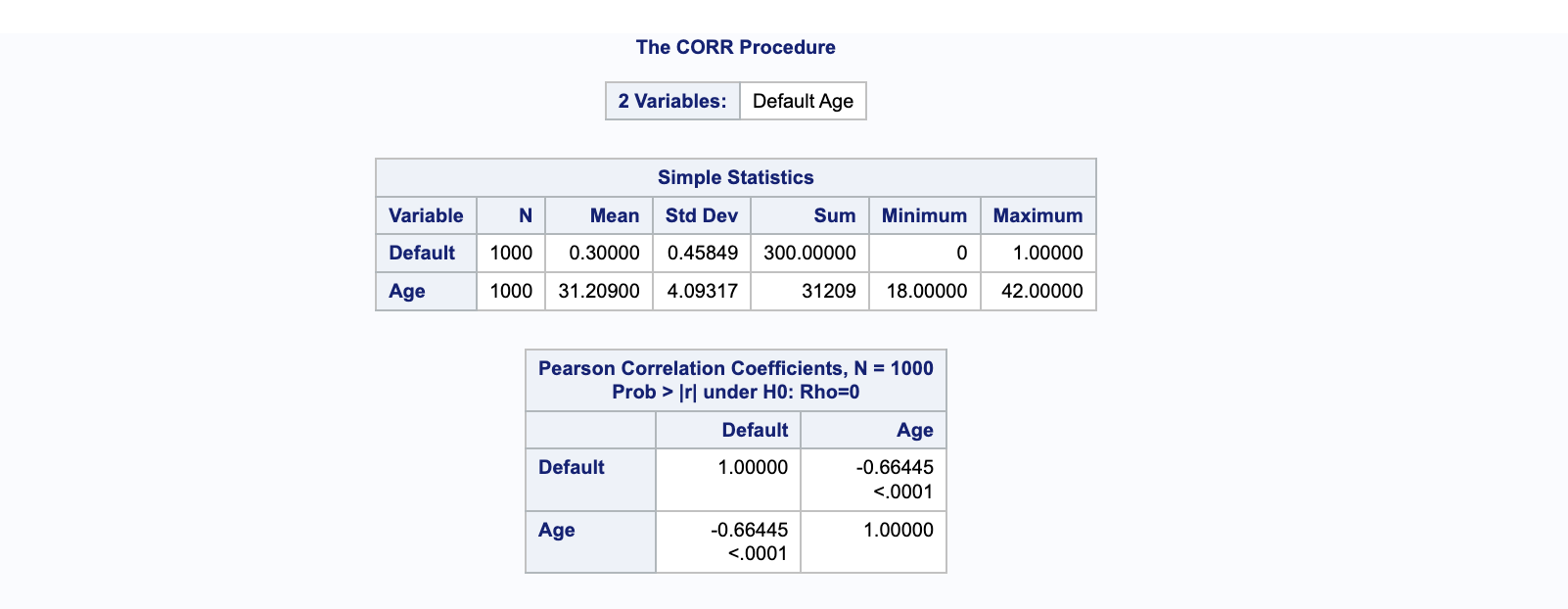
Interprétation des Coefficients de Corrélation de Pearson#
Le coefficient de corrélation entre
DefaultetAgeest de -0.66445. Cette valeur négative indique une corrélation négative, ce qui signifie que lorsque l’âge augmente, la probabilité de défaut de prêt bancaire a tendance à diminuer. En d’autres termes, les deux variables sont inversement proportionnelles l’une à l’autre.Une corrélation de -0.66445 est considérée comme modérément forte, suggérant que l’âge peut être un prédicteur significatif du défaut de prêt bancaire dans le jeu de données analysé.
La même approche peut être utilisée pour calculer la corrélation entre d’autres paires de variables, fournissant ainsi une vision plus complète des relations linéaires présentes dans nos données.
Construction et Interprétation de Modèles sur l’Ensemble des Données#
Construction du Modèle#
Le modèle est construit en utilisant proc logistic avec l’option descending pour indiquer que nous modélisons la probabilité que la variable dépendante Default soit égale à 1. Sans cette option, SAS modéliserait la probabilité de Default = 0.
Code SAS pour la Construction du Modèle#
Dans notre modèle, la variable Default est la variable dépendante tandis que les éléments tels que Checking_amount, Term, Credit_score, Car_loan, Personal_loan, Home_loan, Education_loan, Amount, Saving_amount, Emp_duration, Gender, Marital_status, Age, No_of_credit_acc et Emp_status constituent les variables indépendantes. La régression logistique est appliquée, en se basant par défaut sur une famille binomiale avec un lien logit. Pour évaluer les données defaut_pret, qui se trouvent dans notre bibliothèque de travail biblio, nous utilisons l’instruction score. Le résultat final est ensuite affiché, montrant les données aux côtés des valeurs prédites, et est enregistré dans l’ensemble de données Logistic_result.
*Construction du modèle de régression logistique sur l'ensemble complet des données;
proc logistic data = biblio.defaut_pret descending;
class Gender Marital_status Emp_status / param=effect ref=first;
model default = Checking_amount Term Credit_score Car_loan Personal_loan
Home_loan Education_loan Amount Saving_amount Emp_duration
Gender Marital_status Age No_of_credit_acc Emp_status / link=logit;
score out = Logistic_result;
run;
Dans le code ci-dessus, class est utilisé pour spécifier les variables catégorielles. L’option param=effect ref=first est utilisée pour correspondre aux résultats obtenus dans R, où la première catégorie est omise par défaut.
Interprétation des Résultats#
La sortie partielle, affichée dans ces tableaux, montre les coefficients estimés, leurs erreurs standard, les statistiques de Wald et les valeurs p associées. Seules les variables avec une valeur p inférieure à 0.05 sont considérées significatives et conservées dans le modèle final.
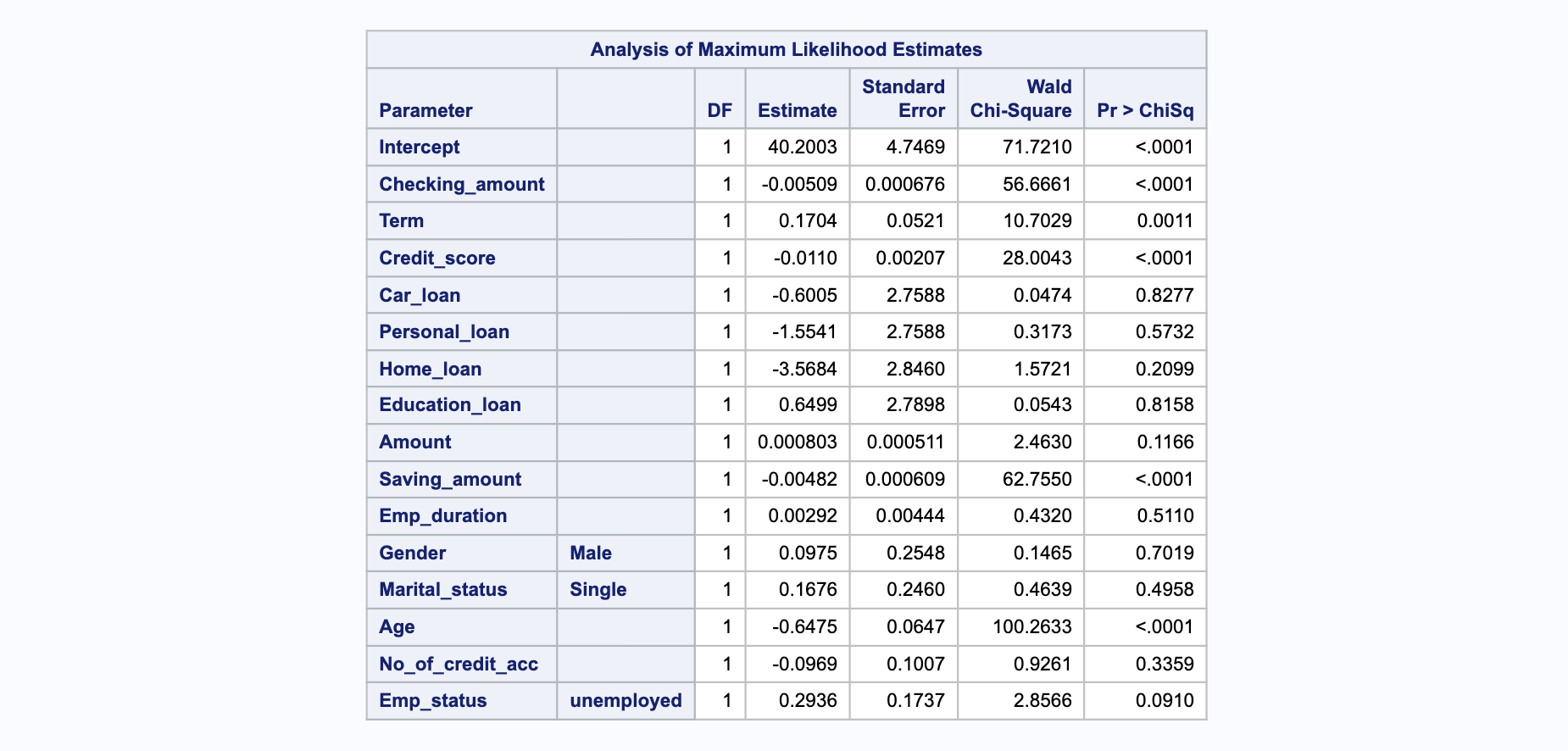
Variables Significatives#
Les variables identifiées comme significatives sont Checking_amount, Term, Credit_score, Saving_amount, et Age. Le modèle final est affiné pour inclure uniquement ces prédicteurs significatifs. Ces variables présentant des valeurs de p inférieures à 0,05 contribuent de manière significative au modèle.
Résultats Finaux#
Le modèle ajusté est utilisé pour scorer l’ensemble de données defaut_pret, et les valeurs prédites sont enregistrées dans l’ensemble de données Logistic_result. Ces étapes illustrent le processus itératif et critique de la modélisation statistique, soulignant l’importance de l’interprétation des données et de la validation du modèle.
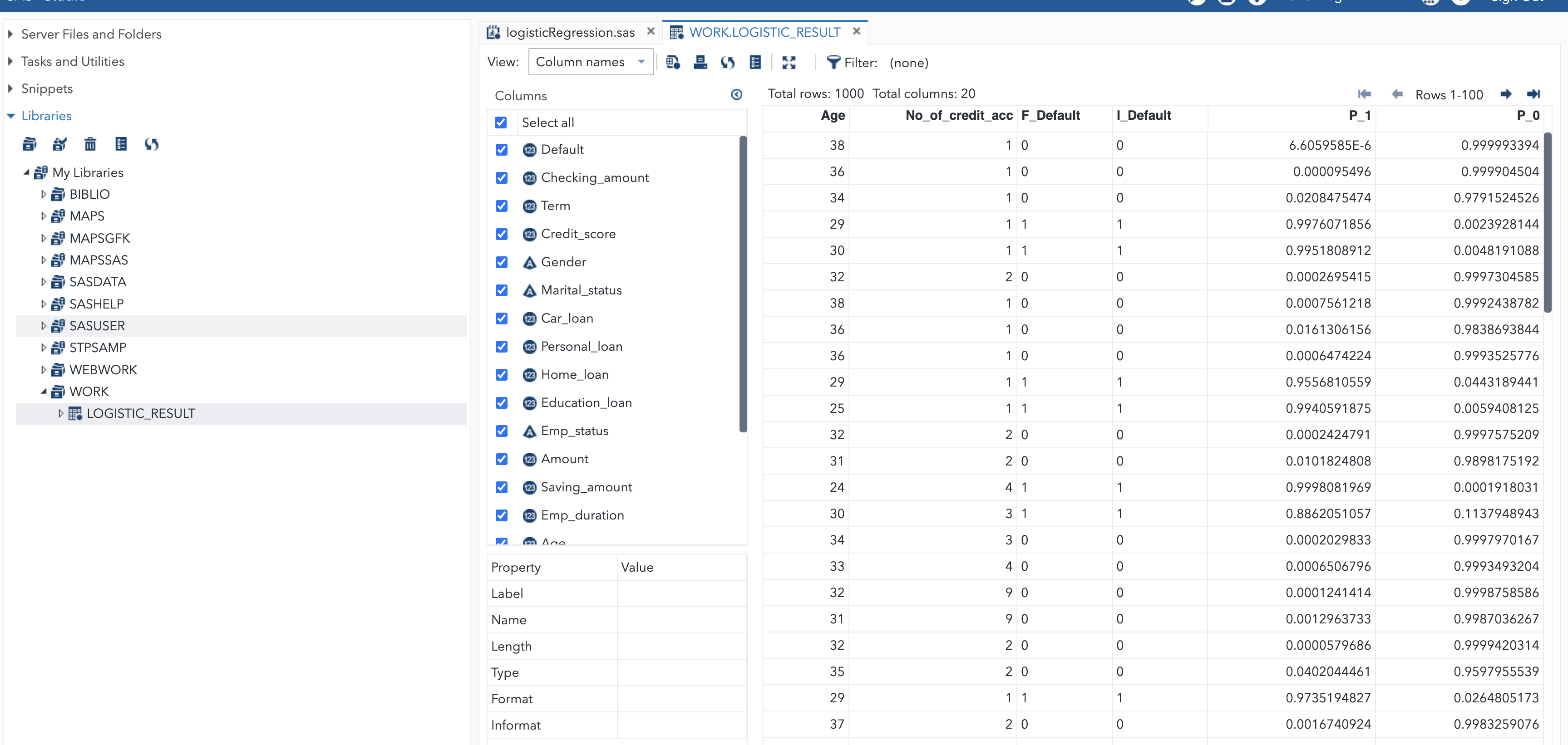
Reconstruction du Modèle Logistique sur l’Ensemble des Données#
Après avoir écarté les variables non significatives de notre jeu de données, nous procédons à la reconstruction du modèle logistique.
* Reconstruction du modèle logistique sur l'intégralité des données après suppression des variables insignifiantes ;
proc logistic data = biblio.defaut_pret descending;
model default = Checking_amount Term Credit_score Saving_amount Age / link=logit;
score out = Logistic_result;
run;
La première et la seconde partie de la sortie de code affichent le fichier loan_default, qui est analysé, ainsi que le nombre total d’observations lues et utilisées dans notre analyse, s’élevant à 1000. Default est la variable dépendante ou cible de notre analyse, et SAS utilise le modèle logit binaire pour la modélisation, avec la technique d’optimisation de Fisher pour le scoring.
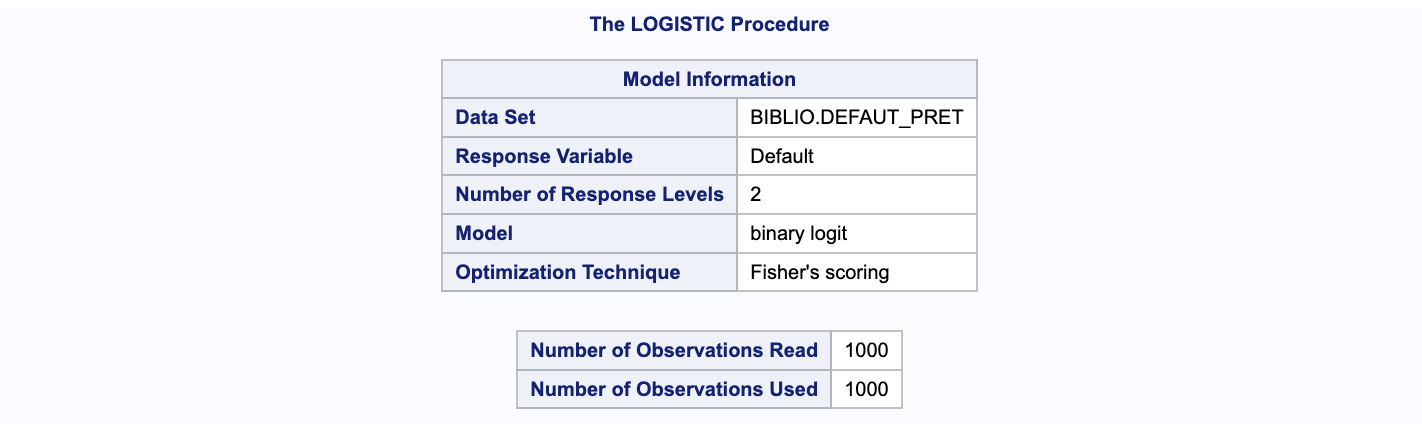
La troisième partie du code indique que nous modélisons la probabilité que Default soit égal à 1, ce qui est indiqué par l’utilisation de l’option descending dans notre code. Sans cette option, SAS modéliserait la probabilité que Default soit égal à 0 et l’interprétation des résultats du modèle serait inversée. Au lieu de calculer la probabilité pour default = 1, le modèle prédirait la probabilité pour Default = 0. Ainsi, il est crucial d’inclure l’option descending dans proc logistic, car par défaut, proc logistic modélise les zéros plutôt que les uns.
La partie 4 des résultats du code, dans la section Statistiques d’Ajustement du Modèle, présente les résultats relatifs à l’ajustement du modèle qui sont utiles pour évaluer l’adéquation globale du modèle. Le modèle complet avec son critère -2 log L (1221.729) est employé pour la comparaison avec le modèle emboîté (Nested model). Les critères d’information AIC et SC sont utilisés dans le modèle pour cette évaluation.

La section suivante expose les résultats concernant le ratio de vraisemblance, le score et le test de Wald. Le ratio de vraisemblance Chi-carré, avec une valeur de (881.7588) pour 5 degrés de liberté et une valeur P associée de 0.0001, indique que notre modèle complet est significativement mieux ajusté par rapport à notre modèle nul. De la même manière, le score du test Chi-carré de (635.5404) avec 5 degrés de liberté et une valeur P de 0.0001 ainsi que le Chi-carré du test de Wald de (186.1945) avec 5 degrés de liberté et une valeur P de 0.0001 confirment également la signification statistique de notre modèle.

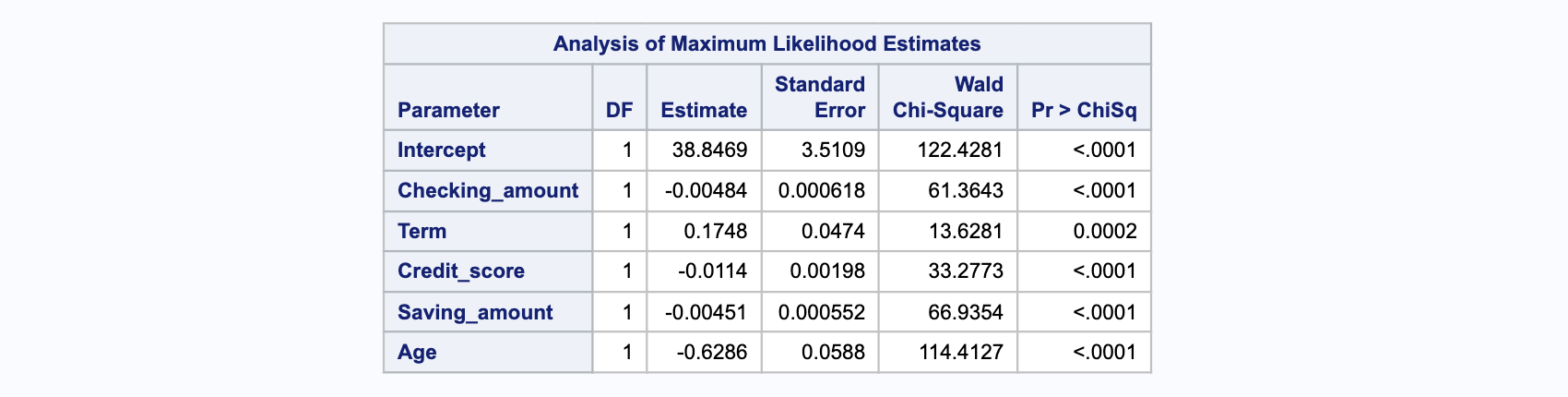
Le tableau ci-dessous présente les coefficients (Estimation), leurs erreurs standard (erreur), la statistique du Chi-carré de Wald et les valeurs-p associées. Ce tableau montre toutes les variables significatives avec des valeurs de p inférieures à 0,05 comme Checking_amount, Term, Credit_score, Saving_amount et Age.
Les coefficients pour Checking_amount, Term, Credit_score, Saving_amount et Age sont statistiquement significatifs car leurs valeurs P sont inférieures à 0,05. Dans le modèle de régression logistique, pour une augmentation d’une unité des variables prédictives, cela se traduit par un changement (augmentation ou diminution) des cotes logarithmiques du résultat. Cela peut être interprété comme suit :
Pour chaque changement d’une unité dans
Checking_amount, les cotes logarithmiques de défaut de prêt bancaire par rapport au non-défaut bancaire diminuent de (-0.004).De même, pour
Term, un changement d’une unité entraîne une augmentation des cotes logarithmiques de défaut de prêt bancaire par rapport au non-défaut bancaire de (0.174).Pour
Credit_score, un changement d’une unité dans le score de crédit diminue les cotes logarithmiques de défaut de prêt bancaire par rapport au non-défaut bancaire de (-0.011).Pour
Saving_amount, un changement d’une unité dans le montant d’épargne diminue les cotes logarithmiques de défaut de prêt bancaire par rapport au non-défaut bancaire de (-0.004).Pour
Age, un changement d’une unité dans l’âge diminue les cotes logarithmiques de défaut de prêt bancaire par rapport au non-défaut bancaire de (-0.628).
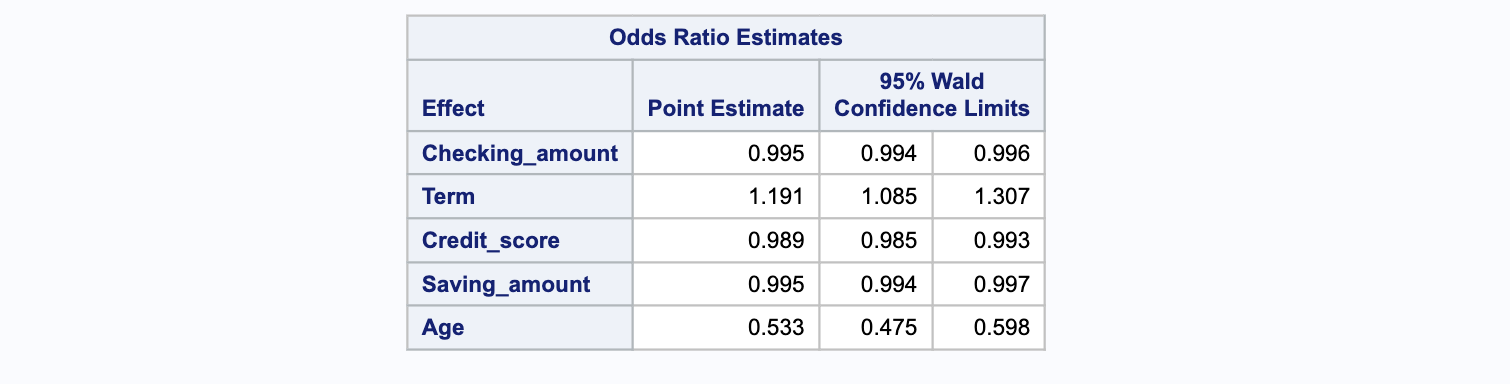
Dans le tableau suivant ci-dessous, on expose l’estimation du rapport de cotes pour chaque variable significative et les intervalles de confiance de Wald à 95% correspondants pour les variables sans interactions. Le rapport de cotes est le coefficient exponentié, par exemple, si la valeur du coefficient pour Checking_amount est de -0.00484, alors exp(-0.00484) est égal à 0.995. De manière similaire, pour le coefficient Term, si la valeur est de 0.1748, alors exp(0.1748) est égal à 1.191, et le même calcul est appliqué pour les autres coefficients exponentiés.
Cela peut être interprété comme suit : par exemple, pour une augmentation d’une unité dans Checking_amount, les chances d’être en défaut de prêt bancaire (par rapport à un non-défaut) diminuent d’un facteur de 0.995. De même, pour une augmentation d’une unité dans Term, les chances d’être en défaut de prêt bancaire (par rapport à un non-défaut) augmentent d’un facteur de 1.191.
En fin, dans la dernière section du résultat du code, l’association entre les probabilités prédictives et les observations réelles est mise en évidence. Cette partie analyse l’efficacité du modèle à estimer correctement la variable cible. On détermine qu’un appariement est concordant si un prêt non défaillant présente une probabilité inférieure à un prêt défaillant, et discordant dans le cas contraire. Lorsque les probabilités prédites pour les deux types de prêt sont identiques, on parle d’appariements neutres.

Le modèle est considéré comme performant s’il génère un nombre élevé d’appariements concordants par rapport aux discordants. Dans notre ensemble de données, compte tenu des demandes de prêt, nous avons un total de 210000 paires à comparer. proc logistic fournit quatre indicateurs statistiques de corrélation pour évaluer la robustesse prédictive du modèle. Parmi ces indicateurs, la statistique C est couramment appliquée pour mesurer la justesse des prédictions. Une valeur élevée de la statistique C traduit une précision prédictive supérieure du modèle.